
|
◯Pandas(パンダス) ・Pythonのデータ操作によく用いられるパッケージ ・pandasのデータフレームは、2次元の表形式のデータセットを提供。SQLと似たような感覚でデータの処理が可能 ・機械学習において、データセットを解析・処理を行う作業にPandasを使うことが標準となっている |
|
◯Pandasとは ・pandasとはpythonのデータ分析ライブラリの1つ ・大きな表データ、行列を扱うことができる ・表計算ソフトの機能の大半は置き換えることができる |
|
◯Pandasのデータ形式 |
| ・Series(シリーズ) | 一次元の配列 |
| ・Dataframe | 2次元の配列データ。seriesを複数まとめたもの |
| ・Panel | 3次元の配列データ |
|
◯Pandasの用語 |
| ・index | 行ラベル |
| ・columns | 列ラベル |
| ・integer-location | 番号指定でデータにアクセスすること |
|
◯03_Seriesの基本 |
| comment | Source | Result |
|---|---|---|
| indexが自動付与される |
s = pd.Series([10, 20, 30]) print(s) |
0 10 1 20 2 30 |
| indexに独自ラベルを指定する |
s = pd.Series([10, 20, 30], index=['a', 'b', 'c']) print(s) |
a 10 b 20 c 30 |
| 辞書から生成 |
s = pd.Series({'a': 10, 'b': 20, 'c': 30}) print(s)
s = pd.Series({'a': 10, 'b': 20, 'c': 30}) print(s['a']) print(s.a) print(s[0:2]) |
a 10 b 20 c 30
10 10 a 10 b 10 |
| Seriesの更新 |
s[0] = 100 print(s) |
a 100 b 20 c 30 |
|
◯04_Seriesの演算 |
| comment | Source | Result |
|---|---|---|
|
s = pd.Series([1, 2], index=['a', 'b']) print(s) |
||
| 足し算 | s + 10 |
a 11 b 12 |
| 引き算 | s - 10 |
a -9 b -8 |
| 掛け算 | s * 2 |
a 2 b 4 |
| 割り算 | s / 2 |
a 0.5 b 1.0 |
| Series同士の演算 |
s1 = pd.Series([1, 2], index=['a', 'b']) s2 = pd.Series([3, 4], index=['a', 'b']) s1 + s2 |
a 4 b 6 |
|
◯05_DataFrameの生成の基本 |
| comment | Source | Result |
|---|---|---|
| index、columnを指定しないで生成 |
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]]) print(df)
column、indexはデフォルト値として0からの数値が設定される |
0 1 0 1 10 1 2 20 2 3 30 |
| index、columnを指定して生成 |
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], index=['a', 'b', 'c'], columns=['col1', 'col2']) print(df)
列名としてcol1、col2が、行名としてa〜cが設定され |
col1 col2 a 1 10 b 2 20 c 3 30 |
| 辞書から生成する |
df = pd.DataFrame({'col1' : [1, 2, 3], 'col2' : [10, 20, 30]}) print(df) |
col1 col2 0 1 10 1 2 20 2 3 30 |
| Seriesから生成 |
s1 = pd.Series([100, 101, 102], index=['a', 'b', 'c']) s2 = pd.Series([100, 101, 102], index=['b', 'c', 'd']) df = pd.DataFrame({'col1': s1, 'col2': s2}) print(df)
Seriesで設定されているindexが同じものを同じ行としてマージ |
col1 col2 a 100.0 NaN b 101.0 100.0 c 102.0 101.0 d NaN 102.0 |
|
◯06_基本統計量の算出 |
| comment | Source | Result | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2']) print(df) |
col1 col2
0 1 10 1 2 20 2 3 30 |
||||||||||||||||||||||||||||
| 行数 |
len(df) |
3 | |||||||||||||||||||||||||||
| 要素数 | df.size |
6 |
|||||||||||||||||||||||||||
| 列毎の要素数 | df.count() |
col1 3 col2 3 |
|||||||||||||||||||||||||||
| 列毎の平均 |
df.mean()
df.mean()['col1'] |
col1 2.0 col2 20.0
2.0 |
|||||||||||||||||||||||||||
| 列毎の最大値 |
df.max() |
col1 3 col2 30.0 |
|||||||||||||||||||||||||||
| 列毎の最小値 |
df.min() |
col1 1 col2 10.0 |
|||||||||||||||||||||||||||
| 基本的な統計量の一括取得(列毎) |
df.describe()
df.describe()['col2']['25%'] |
15.0 |
|
◯07_DataFrameのデータ参照 |
| comment | Source | Result | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2'], index=['a', 'b', 'c']) print(df) |
|
||||||||||||
| col1を取得する | print(df['col1']) |
a 1 b 2 c 3 |
|||||||||||
| col2のa行目を[]で取得 |
print(df.col2['a']) print(df.col2.a) |
10 10 |
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2']) print(df) |
|
|||||||||||||
| スライス(1行以降、2行目未満) |
print(df[1:2])
スライスで指定できるのは行、取得できるのがDataFrame |
|
||||||||||||
| locで行データをSeries形式で取得 |
print(df.loc[0]) |
col1 1 col2 10 |
||||||||||||
| スライス(1行目~2行目) |
print(df.loc[1:2]) |
|
||||||||||||
| locで0行目のcol1のデータを取得 |
print(df.loc[0]['col1']) |
1 |
||||||||||||
| ilocで行データをSeries形式で取得 |
df.iloc[1] |
col1 2 col2 20 |
||||||||||||
| atでindexがaでカラムがcol1のデータを取得 |
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2'], index=['a', 'b', 'c']) df.at['a', 'col1']
loc系は複数要素を抽出できるが、at系は1つのみ |
1 |
||||||||||||
| iatで1行1列目を取得 |
df.iat[1, 1] |
20 |
|
◯08_DataFrameのフィルタリング |
| comment | Source | Result | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([['A', 10], ['B', 20], ['C', 30], ['D', 40]], columns=['col1', 'col2']) df |
|
||||||||||||||||
| indexと同じサイズのbool型のシーケンス(Series)を指定すると、Trueとなるものだけ抽出することができる |
l = [True, False, True, False] df[l]
0番目と2番目がTrueなので、0行目と2行目が抽出される |
|
|||||||||||||||
| indexが偶数の列を表すシーケンスを取得(array([ True, False, True, False]))。この演算を利用して抽出 |
df[df.index % 2 == 0] |
|
|||||||||||||||
| 特定列で条件に完全一致するものを抽出 | df[df.col1=='C'] |
|
|||||||||||||||
| 特定列で条件より大きいものを抽出 | df[df.col2 > 10] |
|
|||||||||||||||
| 正規表現でフィルタ |
cond = df.col1.str.contains('.*A') df[cond] |
|
|
◯09_whereによるフィルタリング |
| comment | Source | Result | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30], [4, 40]], columns=['col1', 'col2']) df |
|
||||||||||||||||
| whereでは元のDataFrameと同じサイズで該当するもの以外はNaNが設定される | df.where(df['col1'] > 2) |
|
|||||||||||||||
|
df[df['col1'] > 2]
添字でフィルタ条件を指定した場合は該当するものだけ抽出される |
|
||||||||||||||||
| 第2引数でNanの場合の初期値を設定できる | df.where(df['col1'] > 2, 0) |
|
|||||||||||||||
|
第2引数に埋める値のDataFrameを指定すると、セル毎に埋める値を分けることが可能
例 col1は0, col2はハイフンで埋める場合 |
pad = pd.DataFrame([[0, '-']] * len(df), columns=df.columns, index=df.index) pad |
|
|||||||||||||||
|
df.where(df['col1'] > 2, pad) |
|
|
◯10_DataFrameのソート |
| comment | Source | Result | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[3, 10, 200], [3, 30, 100], [2, 40, 300], [1, 20, 200]], columns=['col1', 'col2', 'col3']) df |
|
|||||||||||||||||||||
| col1 昇順、col2 降順でソート | df.sort_values(['col1', 'col2'], ascending=[True, False]) |
|
|
◯11_DataFrameの更新系処理 |
| comment | Source | Result | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2'], index=['a', 'b', 'c']) df |
|
|||||||||||||||||||
| s = pd.Series([1, 1, 1], index=['a', 'b', 'c']) |
a 1 b 1 c 1 |
|||||||||||||||||||
|
Seriesを新たな列 として追加 |
df['col3'] = s df |
|
|
|||||||||||||||||
| 既存列を更新 |
df['col1'] = s df |
|
||||||||||||||||||
|
df = pd.DataFrame([[1, 10], [2, 20]], columns=['col1', 'col2'], index=['a', 'b']) df2 = pd.DataFrame([[9, 99]], columns=['col1', 'col2'], index=['c']) |
|
|||||||||||||||||||
| 行の追加 |
df.append(df2) |
|
||||||||||||||||||
| 行の削除 |
df.drop('a')
indexはリストで複数指定可 df.drop(['a', 'b'])
|
|
||||||||||||||||||
| 列の削除 |
df.drop('col1', axis=1) |
|
||||||||||||||||||
| 要素の更新 |
df.at['a', 'col1'] = 999 df |
|
|
◯12_DataFrameのループ処理 |
| comment | Source | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2']) df |
|
|||||||||||||
|
1行ずつループ(rowはSeries型)
|
for index, row in df.iterrows(): print(index, row['col1'], row['col2'])
for index, row in df.iterrows(): print(df.col2[index]) |
0 1 10 1 2 20 2 3 30
10 20 30 |
||||||||||||
| 一列ずつループ |
i=1 for index, col in df.iteritems(): print("i> {}".format(i)) print(col) i+= 1 |
i> 1 0 1 1 2 2 3 i> 2 0 10 1 20 2 30 |
||||||||||||
|
i=1 for index, col in df.iteritems(): print("{}:{}".format(i,sum(col))) i+= 1 |
1:6 2:60 |
|||||||||||||
|
|
||||||||||||||
|
|
|
|
◯13_欠損値(NaN) |
| comment | Source | Result | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
import pandas as pd import math |
|||||||||||||||||
|
s = pd.Series([2, 5, 8, None]) s |
0 2.0 1 5.0 2 8.0 3 NaN |
||||||||||||||||
| NaNの判定 |
for num in s: print(math.isnan(num)) |
False False False True |
|||||||||||||||
| pd.isnull(s) |
0 False 1 False 2 False 3 True |
||||||||||||||||
| 欠損値NaNを除去 | s.dropna() |
0 2.0 1 5.0 2 8.0 |
|||||||||||||||
|
df = pd.DataFrame([[1, None], [None, 20], [None, None], [4, 40]], columns=['col1', 'col2']) df |
|
||||||||||||||||
| どれか1つでもNaNがあれば除去 |
df.dropna() |
|
|||||||||||||||
| col1でNaNがあるものが除去 |
df.dropna(subset=['col1']) |
|
|||||||||||||||
|
df = pd.DataFrame([[1, 10], [None, 20], [3, 30], [4, 40]], columns=['col1', 'col2']) df |
|
||||||||||||||||
| 欠損値がある列を除去する |
df.dropna(axis=1) |
|
|
◯14_column(列名) index(行名)の変更 |
| comment | Source | Result | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20]], columns=['col1', 'col2'], index=['a', 'b']) df |
|
||||||||||
| 列名を変更する |
new_df = df.rename(columns={'col1': 'new1', 'col2': 'new2'}) new_df |
|
|||||||||
| 行名を変更する |
new_df = df.rename(index={'a': 'new1', 'b': 'new2'}) new_df |
|
|||||||||
|
inplace=Falseでは元のDataFrame は変更されない |
df.rename(columns={'col1': 'new1', 'col2': 'new2'}, inplace=False) df |
|
|||||||||
|
inplace=Trueで元のDataFrame が変更される |
df.rename(columns={'col1': 'new1', 'col2': 'new2'}, inplace=True) df |
|
|
◯15_DataFrameをgroupbyで集計する |
| comment | Source | Result | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([ ['cate1', 'tag1', 150], ['cate1', 'tag1', 210], ['cate1', 'tag2', 20], ['cate2', 'tag2', 80], ['cate2', 'tag1', 310], ], columns=['category', 'tag', 'value']) |
|
|||||||||||||||||||||||||
| categoryごとの合計を算出する | df.groupby(['category', 'tag']).count() |
|
||||||||||||||||||||||||
| tagごとのばらつきを算出する |
df.groupby(['tag']).std()
std( )は標準偏差(サイト)を求めばらつきを確認する時に使用
|
|
|
◯16_DataFrameの値を置換する |
| comment | Source | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
import pandas as pd import numpy as np |
||||||||||||||
|
df = pd.DataFrame([['apple', 10], ['oranggg', 20], ['banana', 30]], columns=['name', 'price']) df |
|
|||||||||||||
| replaceメソッドで置換 | df.replace('oranggg', 'orange') |
|
||||||||||||
| 正規表現による置換 | df.replace('.*ggg.*', 'orange', regex=True) |
|
||||||||||||
|
df = pd.DataFrame([[1, 10], [None, 20], [3, None]], columns=['col1', 'col2']) df |
|
|||||||||||||
| 欠損値の0埋め |
df.replace(np.NaN, 0) |
|
|
◯17_ピボットテーブル |
| comment | Source | Result | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([ ['cate1', 'tag1', 4], ['cate2', 'tag1', 10], ['cate1', 'tag2', 5], ['cate3', 'tag3', 5], ['cate2', 'tag3', 5]], columns=['category', 'tag', 'value']) df |
|
|||||||||||||||||||||||||
| 合計をクロス集計する |
df.pivot_table(index=['category'], columns=['tag'], values='value', fill_value=0, aggfunc=lambda x: sum(x))
index:縦の集計項目を指定。複数指定可 columns:横の集計項目を指定します。複数指定可 values:集計対象の値の項目を指定 fill_value:NaNを何で埋めるか aggfunc:集計関数を指定
・個数 aggfunc=lambda x: len(x) ・平均 aggfunc=lambda x: np.average(x) ・標準偏差 aggfunc=lambda x: np.std(x)
|
|
|
◯18_DataFrameの行列を入れ替える |
| comment | Source | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
df = pd.DataFrame([[1, 10], [2, 20], [3, 30]], columns=['col1', 'col2'], index=['a', 'b', 'c']) df |
|
|||||||||||||
| indexをcolumnに、columnをindexに置換 | df.T |
|
|
◯20_DataFrame CSV、TSV形式で入出力 |
| comment | Source | Result | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ・ ファイル入力 |
|
|
||||||||||||||||
| CSV、TSVを読み込む |
df = pd.read_csv('data.tsv', sep='\t')
CSVもTSVもread_csvメソッドを使用 区切り文字のデフォルトはカンマ
|
|
||||||||||||||||
|
df = pd.read_csv('data.tsv', sep='\t', header=None)
ヘッダーがない場合はheader=Noneを指定 |
|
|||||||||||||||||
| ・ファイル出力 |
|
|||||||||||||||||
| TSV形式でindexを出力しない |
df.to_csv('output.tsv', sep='\t', index=False)
|
0 1 2 S1 PC-A 500 S2 PC-B 850 S3 PC-C 120 |
||||||||||||||||
| TSV形式でindexを出力する |
df.to_csv('output.tsv', sep='\t', index=True, index_label='col')
行インデックスの列名を指定 |
col 0 1 2 0 S1 PC-A 500 1 S2 PC-B 850 2 S3 PC-C 120 |
|
◯21_DataFrame excelファイルで入出力 |
| comment | Source | Result |
|---|---|---|
| 最初のシートを読み込む |
df = pd.read_excel('kokyaku_daicho.xlsx')
|
|
| シート名を指定し、1行目をスキップ |
df = pd.read_excel('kokyaku_daicho.xlsx', sheet_name="Sheet1", skiprows=1)
|
|
| とりあえず書き出す |
df.to_excel('output.xlsx')
|
|
| シート名を指定する |
df.to_excel('output.xlsx',sheet_name='Sheet1')
|
|
|
◯22_DataFrame htmlで入出力 |
| comment | Source |
|---|---|
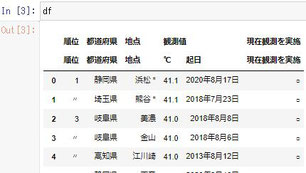
| htmlを取得しtableタグの中身をDataFrameに格納 |
dfs = pd.read_html('https://www.data.jma.go.jp/obd/stats/etrn/view/rankall.php?prec_no=&block_no=&year=2017&month=&day=&view=') df = dfs[0]
dfs[0] ・・・最初のtableタグ dfs[1] ・・・2番目のtableタグ |
|
requestsでhtml を取得 |
import requests r = requests.get('https://www.data.jma.go.jp/obd/stats/etrn/view/rankall.php?prec_no=&block_no=&year=2017&month=&day=&view=') r.encoding = 'UTF-8' html = r.text |

|
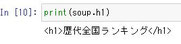
BeautifulSoupから必要となるデータを抽出 |
from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html5lib") |
|
◯23_DataFrame クリップボードで入出力 |
| comment | Source | Result |
|---|---|---|
| クリップボードから読み込む |
エクセルなどで適当な範囲がクリップボードにコピーされている状態から df = pd.read_clipboard(sep='\t') df |
|
| クリップボードに書き込む |
df.to_clipboard() 上記を実行してエクセルでペーストするとDataFrameの内容が出力される |
|
|
◯24_DataFrame DB入出力 |
| comment | Source | Result | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
import sqlite3 import pandas as pd import pandas.io.sql as psql |
||||||||||||||||||||||
| sqlite3に接続 |
con = sqlite3.connect(':memory:') cur = con.cursor() |
|
||||||||||||||||||||
| テーブルを作成 |
cur.execute('CREATE TABLE articles (id int, title varchar(1024), body text, created datetime)')
|
<sqlite3.Cursor at 0x14ee296ed50> |
||||||||||||||||||||
| テーブルにデータを挿入 |
cur.execute('insert into articles values (1, "sample1", "AAAA", "2017-07-14 00:00:00")') cur.execute('insert into articles values (2, "sample2", "BBBB", "2017-07-15 00:00:00")')
|
<sqlite3.Cursor at 0x14ee296ed50> |
||||||||||||||||||||
|
Select文からDataFrameを作成 |
df = psql.read_sql("SELECT * FROM articles;", con) df
|
|
||||||||||||||||||||
|
テーブルにデータ追加するためのDataFrameを作成 |
df2 = pd.DataFrame([['sample3', 'CCC', '2017-07-16 00:00:00']], columns=['title', 'body', 'created'], index=[2]) df2
|
|
||||||||||||||||||||
|
DataFrameの内容をDBに格納 |
df2.to_sql('articles', con, if_exists='append', index=None)
if_existsはデータが既存の場合の挙動。appendかreplece
|
|
||||||||||||||||||||
|
Select文からDataFrameを作成 |
df = psql.read_sql("SELECT * FROM articles;", con) df
|
|