
❏ 第2部 実践編①:機械学習 - まとめ
機械学習
|
機械学習の基礎 |
Appending② |
・機械学習の主軸は未来の予測
・機械学習を大きく分けると教師あり学習、教師なし学習、強化学習の3つに分けられる
・教師あり学習とは
・既に正解がわかっているデータ(教師データ)をコンピュータに学習させる方法
・分類と回帰がある。利用回数のような連続値が回帰、退会する/しないのような非連続地が分類
・分類のアルゴリズム:決定木、ロジスティック回帰、ランダムフォレストなど(沢山ある)
・回帰のアルゴリズム:重回帰
・教師なし学習とは
・教師データを学習させずに与えられたデータから規則性などの意味のある情報を見つけ出す手法
・代表的なものみクラスタリングがある
・クラスタリングでは利用顧客などのデータをコンピュータでグループ分けして、そのグループ毎に傾向を把握し施策につなげる
・階層的クラスター分析(分類対象が少ない時に用いる)と非階層的クラスター分析(あらかじめグルーピングしたい数を指定する)がある
・強化学習とは
・一連の行動に対して報酬などを与えて、どのような行動が最も報酬が高くなるかを学習していく手法
・AlphaGo(コンピュータ囲碁プログラム)は強化学習を活用している
|
K-means法 |
ノック32 |
・クラスタリングの手法の中で最もオーソドックスな手法
・非階層的クラスター分析の代表的な手法がK-means法
・scikit-learn(サイキット・ラーン)というライブラリをインポートする
| ・手順) | 1 データ標準化 | 標準化データ = sc.fit_transform(データ) |
| 2 モデル定義 | モデル = KMeans(n_clusters=クラスタ数, random_state=0) | |
| 3 モデル構築 | 結果 =モデル.fit(標準化データ) → 結果.labels_にクラスタ番号が入っている |
|
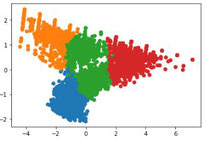
次元削除 |
ノック34 |
・教師なし学習の一種
・複数の変数を二次元上にプロット(描画する、点を打つ)する場合、次元削除を行う
・情報をなるべく失わないよに3つ以下に変数を削除することで、グラフ化が可能になる
・次元削除の代表的な手法は主成分分析(PCA)
・scikit-learn(サイキット・ラーン)というライブラリをインポートする
| ・手順) | 1 データ標準化 | 標準化データ = sc.fit_transform(データ) |
| 2 モデル定義 | モデル = PCA(n_components=2) | |
| 3 モデル構築 | モデル.fit(標準化データ) | |
| 結果 =モデル.transform(標準化データ) | ||
| 4 データ加工 | クラスタリング列と次元削除の結果をマージする | |
| 5 グラフ化 | グループ毎に次元削除の結果(x変数とy変数)をプロット |
|
線形回帰モデル |
ノック38 |
・線形回帰とは、回帰分析の一種で、ある目的変数の値を、別の説明変数の値に基づいて予測する手法のこと
・予測したいデータ・値を目的変数、予測するために使用するデータのことを説明変数と言います
・学習用データで学習を行い、モデルにとって未知のデータである評価用データで精度の検証を行う
・scikit-learn(サイキット・ラーン)のLinearRegression(リニア・リグレッション)を使用
| ・手順) | 1 説明変数を定義 | X = df1[["説明変数のカラム_1","説明変数のカラム_2","説明変数のカラム_3"]] |
| 2 目的変数の定義 | y = df1["目的変数のカラム"] | |
| 3 学習用/評価用に分割 | X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y) | |
| 4 インスタンス生成 | model = linear_model.LinearRegression() | |
| 5 学習用データでモデル作成 | model.fit(X_train, y_train) |
・決定係数(寄与率)とは、説明変数が目的変数をどのくらい説明できるかを表す値で高ければ高いほど良いとされている
・決定係数(寄与率)はscoreによって出力される
| ・手順) | 1 学習用データのscore | print(model.score(X_train, y_train)) |
| 2 評価用データのscore | print(model.score(X_test, y_test)) |
モデルの分析 ノック39
・説明変数ごとに、モデルに寄与している変数の係数(寄与度)を出力
| ・手順) | 1 寄与度出力 | coef = pd.DataFrame({"feature_names":X.columns, "coefficiet":model.coef_}) |
来月の利用回数を予測 ノック40
| ・手順) | 1 説明変数の設定 | x1 = [3, 4, 4, 6, 8, 7, 8]; x2 = [2, 2, 3, 3, 4, 6, 8]; x_pred = [x1, x2] |
| 2 予測 | model.predict(x_pred) | |
| 3 標準出力 | array([3.90828584, 2.0039648 ]) |
|
決定木 |
ノック47 |
・教師あり学習の分類アルゴリズムの一つで、退会する/しない、購買する/しない、などの予測に用いられる(分類ルールの可視化)
・決定木単体では高い精度は見込めない
・決定木をアンサンブル学習したランダムフォレストやxgboost(エックスジーブースト)と組み合わせることで最強の精度をたたき出せる
| ・手順) | 1 説明変数を定義 | X = pd.concat([退会顧客データ, 退会顧客と同件数の継続顧客データ], ignore_index=True) |
| 2 目的変数の定義 | y= X["退会フラグ"] | |
| 3 学習用/評価用に分割 | X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y) | |
| 4 インスタンス生成 | model = DecisionTreeClassifier(random_state=0) | |
| 5 学習用データでモデル作成 | model.fit(X_train, y_train) | |
| 6 評価データの予測を行う | y_test_pred = model.predict(X_test) |
モデル評価の確認 ノック48
| ・手順) | 1 学習用データのscore | print(model.score(X_train, y_train)) |
| 2 評価用データのscore | print(model.score(X_test, y_test)) |
・機械学習の目的はあくまで未知のデータへの適合。学習用データで予測した精度と評価用データで予測した精度の差が小さいのが理想
・学習用データに適合しすぎている場合(過学習傾向)、データを増やしたり、変数を見直したり、モデルのパラメータを変更する
・決定木の階層(max_depth)を浅くすることでモデルを簡易化することができ、未知のデータに対応することができる
| model = DecisionTreeClassifier(random_state=0, max_depth=5) |
モデルの分析 ノック49
・説明変数ごとに、モデルに寄与している変数の係数(寄与度)を出力
・ノック39の回帰の時と違い、model.feature_importances_で重要変数を取得できる
| ・手順) | 1 寄与度出力 | X = pd.concat([退会顧客データ, 退会顧客と同件数の継続顧客データ], ignore_index=True) |
顧客の退会を予測 ノック50
| ・手順) | 1 説明変数の設定 | input_data =[3, 1, 10, 0, 1, 1, 0, 0] |
| 2 予測 | print(model.predict([input_data])) | |
| 3 予測確率 | print(model.predict_proba([input_data])) |
処理フロー
|
◯この章の概要 ・クライアントから提供された情報を読み込み顧客行動の分析を行い、取り扱っているデータがどのようなものであるかを把握 |
| ノック | 概要 | データフレーム | 説明 | 主な関数 | |
|---|---|---|---|---|---|
| 21 | データの読み込み | in |
uselog customer など |
・ファイルをpandasのデータフレーム型に格納 | ・pd.read_csv |
| 22 |
顧客データの整形 ※顧客情報を一つ にしたもの |
in
out |
customer class_master など customer_join |
・データ同士をJOIN ・欠損値の確認 |
・pd.merge ・isnull().sum() |
| 23 | 顧客データの把握 | in | customer_join |
・会員区分やキャンペーン区分別等の人数を集計 ・入会人数を集計 ・現場の人へのヒアリング、仮説を立てる |
・groupby、count ・loc |
| 24 | 最新顧客データの取得 |
in out |
customer_join customer_newer |
・直近の年月時に在籍していたユーザーを抽出 | ・loc |
| 25 | 利用履歴データを集計 |
in out |
uselog uselog_months uselog_customer |
・利用履歴データを年月・顧客毎に集計 ・顧客毎に年月の平均値、中央値、最大値、最小値を求める |
・groupby、rename、del ・agg |
| 26 | 重要ファクターの設定 |
in out |
uselog uselog_weekday |
・以下の条件を重要ファクターと定義。その情報を求める 「同じ曜日を月4回以上の利用者のroutine_flgを1へ」 |
・weekday、.groupby、 max、where |
| 27 | 顧客データに情報付加 |
in
out |
customer_join uselog_customer uselog_weekday customer_join |
・ノック22:顧客データ(customer_join)にノック25:利用 履歴データ(uselog_customer)、ノック26:定期利用フ ラグ(routine_flg)を付加 |
・merge |
| 28 | 会員期間も付加 |
in out |
customer_join customer_join |
・start_dateからend_dateまでの月数(membership_period) を算出。未退会データは2019/04/30までで計算する |
・fillna、range、 relativedelta、iloc |
| 29 | 列毎の統計情報の確認 | in | customer_join |
・各列の平均、標準偏差、最大値、最小値等を取得 ・定期利用フラグ毎の件数 ・会員期間をヒストグラムで表示 |
・describe ・groupby ・hist |
|
30
|
退会/継続の違い把握 | in | customer_join | ・退会ユーザーと継続ユーザーのdescribeの違いを検証 | ・describe、loc |
|
◯この章の概要 ・クラスタリングを用いて、各グループの行動パターンを掴む ・回帰アルゴリズムで利用回数を夜予測する |
| ノック | 概要 | データフレーム | 説明 | 主な関数 | |
|---|---|---|---|---|---|
| 31 | データの読み込み | out |
uselog customer |
・ファイルをpandasのデータフレーム型に格納 | ・pd.read_csv |
| 32 | 顧客をグループ化 |
in out |
customer customer_clustering |
・クラスタリングを用いて顧客をグループ分けする ノック25で生成した顧客毎の利用履歴に関するデータを使用 |
「機械学習のまとめ」参照 |
| 33 | クラスタリング結果の分析 | in | customer_clustering |
・グループ毎の件数を集計 ・グループ毎の平均値を算出し、各グループの特徴を分析 |
・groupby、count ・mean |
| 34 | クラスタリング結果を可視化 | in | customer_clustering |
・次元削除を用いてグラフ化する ノック32で標準化したデータを使用 |
「機械学習のまとめ」参照 |
| 35 | 退会顧客の把握 | in |
customer_clustering customer |
・クラスタリング結果と顧客データを結合 ・グループ・退会フラグ毎に集計 ・グループ・定期利用フラグ毎に集計 |
・concat ・groupby、count ・同上 |
| 36 | 翌月の利用回数の予測準備 |
in out |
uselog predict_data |
・顧客毎に各年月の利用回数を集計。次に縦に直近6ヶ月(i) 横に(i)を起点した過去6ヶ月の利用回数を展開する |
・groupby、count、 conca |
| 37 | 特徴となる変数の付与 |
in
out |
predict_data customer predict_data |
・会員期間(start_date~年月)を付与 | ・relativedelta |
| 38 | 利用回数予測モデルを作成 |
in out |
predict_data X、y、model |
・古い顧客は入店時情報がない為、開始≧20180401に絞る ・来月の利用回数モデルを作成 |
「機械学習のまとめ」参照 |
| 39 | 寄与してる変数の確認 |
in
|
X、model |
・各説明変数の寄与率を確認 |
「機械学習のまとめ」参照 |
| 40 | 来月の利用回数を予測 | in | model |
・自作した説明変数で目的変数を予測する ・来月の利用回数を予測 |
「機械学習のまとめ」参照 |
|
◯この章の概要 ・分類アルゴリズムで退会顧客を予測する |
| ノック | 概要 | データフレーム | 説明 | 主な関数 | |
|---|---|---|---|---|---|
| 41 | データの読み込み | out |
customer uselog_months uselog |
・ファイルをpandasのデータフレーム型に格納
・当月と過去1ヶ月の利用回数データの生成 |
・pd.read_csv
・loc、merge、concat |
| 42 |
退会顧客データの生成 ※年月(退会前月)・顧客で一意 |
in
out |
customer uselog exit_uselog |
・customerを退会データに絞り、退会の前月列を追加 ・上記の退会前月列をキーにしてuselogにマージ ・退会前月と結合しなかったデータを除外 |
・relativedelta ・merge ・dropna |
| 43 |
継続顧客データの生成 ※年月(任意)・顧客で一意 |
in
out |
customer uselog predict_data |
・継続顧客に絞り、顧客をアンダーサンプリングする
・退会顧客データと継続顧客データをマージ |
・sample、drop_duplicates ・concat |
| 44 | 在籍期間を追加 |
in out |
predict_data predict_data |
・会員期間(start_date~年月)を付与(ノック37と同様) | ・relativedelta |
| 45 | 欠損値を除去 |
in out |
predict_data predict_data |
・継続/退会の両方が持っている列で欠損値データを除外 | ・isna、dropna |
| 46 | ダミー変数化 |
in out |
predict_data predict_data |
・今回の予測に使用するデータに絞り込む ・ダミー変数中、その列が無くても判断可能な列を削除 |
・get_dummies ・del |
| 47 | 退会予測モデルを作成 |
in out |
predict_data model、results_test |
・継続データを退会データの件数に合わせる ・モデルを構築し、評価データの予測を行う |
「機械学習のまとめ」参照 |
| 48 | モデル評価&チューニング |
in out |
predict_data model |
・予測モデルの正解率を算出 ・モデルパラメータの変更 |
「機械学習のまとめ」参照 |
| 49 | 寄与してる変数の確認 |
in
|
X、model | ・各説明変数の寄与率を確認 | 「機械学習のまとめ」参照 |
| 50 | 顧客の退会を予測 | in | model |
・自作した説明変数で目的変数を予測する ・顧客の大会を予測 |
「機械学習のまとめ」参照 |
| グループ | 関数名 | 概要 | 例 |
|---|---|---|---|
| 入出力 | to_csv | ファイル出力する | df1.to_csv("hoge.csv", index=False) |
| 入出力 | DataFrame | データフレームの生成 | df = pd.DataFrame() |
| 抽出 | loc | 条件に合致するデータを抽出 | df2 = df1.loc[df1["date1"] > pd.to_datetime("20180401")] |
| 抽出 | iloc | 行番号で任意のデータを抽出 | df1["col1"].iloc[i] = delta.years*12 + delta.months |
| 加工 | merge | データフレームをjoinする | df3 = pd.merge(df1, df2, on="class", how="left") |
| 加工 | concat | データフレームをunionする(joinも可能) | df3 = pd.concat([df1, df2], ignore_index=True) |
| 加工 | unique | 重複を除外 | df1["end_date"].unique() |
| 加工 | strftime | フォーマット変換 | df1["年月"] = df1["date1"].dt.strftime("%Y%m") |
| 加工 | rename | カラム名の変更 | df1.rename(columns={"col1":"col2"}, inplace=True) |
| 加工 | del | 列の削除 | del df1["col1"] |
| 加工 | reset_index | indexの振り直し | df1 = df1.reset_index(drop=False) |
| 加工 | columns | 全列名の変更 | df1 = ["col1", "col2", "col3"] |
| 加工 | reset_index | indexを初期化 | df = df.reset_index(drop=True) |
| 加工 | astype | str型に変化 | res = df["col1"].astype("str").str.isdigit() |
| 加工 | sample | シャッフルする(frac=1で全件) | df = df.sample(frac=1).reset_index(drop=True) |
| 加工 | drop_duplicates | 重複データの最初のデータのみ取得 | df = df.drop_duplicates(subset="col1") |
| 加工 | get_dummies | ダミー変数化 | df = pd.get_dummies(df) |
| 欠損値 | fillna | 欠損値を他の値に置換 | df1["col1"] = df1["col1"].fillna(pd.to_datetime("20190430")) |
| 欠損値 | isnull | True(欠損値)/Falseを返す | df1.isnull().sum() |
| 欠損値 | isna | isnullと同じ | df.isna().sum() |
| 欠損値 | dropna | 欠損値を含むデータを除去 | df = df.dropna() |
| 日付 | to_datetime | datetime型に変換 | df1["date1"] = pd.to_datetime(df1["date1"]) |
| 日付 | weekday | 曜日番号の取得(月曜:0、日曜:6) | df1["weekday"] = df1["dat1"].dt.weekday |
| 日付 | relativedelta | 日付を加減算 | delta = relativedelta(df1["date2"].iloc[i], df1["date1"].iloc[i]) |
| 集計 | count | データ件数を集計 | df1.groupby("col1").count()["col2"] |
| 集計 | sum | 合計を算出 | df1.isnull().sum() |
| 集計 | agg | 列1毎に列2の平均、中央値等を算出 | df2 = df1.groupby("列1").agg(["mean","median","max","min"])["列2"] |
| 集計 | max | 最大値を取得 | df1 = df1.groupby("col1", as_index=False).max()[["col1", "col2"]] |
| 集計 | describe | 各列の平均、標準偏差、最大値、最小値等を取得 | df1[["col1", "col2", "col3"]].describe() |
| 判定 | where | 条件がTrue:元の値、False:指定値を返す | df1["col1"] = df1["col1"].where(df1["col2"]<4, 1) |
| 判定 | groupby | グルーピング | df1.groupby("col1").count()["col2"] |
| 判定 | range | 連番を生成 | for i in range(len(df1)): |
| 判定 | len | データフレームのデータ件数 | print(len(df1)) | for i in range(6, len(リスト)): |
| 判定 | isdigit | すべての文字が数字ならTrue、以外はFalse | res = df["col1"].astype("str").str.isdigit() |
| 図 | hist | ヒストグラム | plt.hist(df1["col1"]) |