
Amazon Web Services クラウドプラクティショナー
❏ 参考書

正誤情報 https://www.sbcr.jp/support/15130/

AWS 認定クラウドプラクティショナー
模擬試験問題集(7回分455問)
https://www.udemy.com/course/aws-4260/
- ホワイトペーパーの確認(位置No.22)
- おさえておきたい試験当日10のポイント https://blog.trainocate.co.jp/blog/aws10points2_005
❏ 第2章 AWS クラウドの概念
2-1 クラウドとは
|
AWSのようなクラウドサービスプラットフォームからインターネット経由でITリソースをオンデマンドで利用できるサービスの総称 |
29頁 |
2-2 AWSの長所と短所
|
AWSクラウドコンピューティングの6つのメリット |
30頁 |
1.固定費(設備投資費)が柔軟な変動費へ
オンプレミスでは事前投資が必要だったが、クラウドでは利用したいときに利用した分だけ支払う方法に変えられる
既存システムの総所有コストを削減することで、新規システムへの投資を柔軟に行うことが出来る
2.スケールによる大きなコストメリット
従量課金制の料金を低く提供している。過去に60回を超える値下げを行っている
3.キャパシティ予測が不要に
AWSでは必要に応じてリソースの増減を行うことが出来るので、最大インフラ容量を予測する必要がない
4.速度と俊敏性の向上
クラウドなら、分単位の短い時間を要するだけで開発者が新しいITリソースを利用可能
迅速なリソース調達が可能になり、システムの負荷やサービスの拡充に応じて柔軟な構成変更が可能になった
5.データセンターの運用と保守への投資が不要に
クラウドを利用することで、サーバーの設置、連携、起動といった重労働が不要になり、ユーザーに直結した業務に専念することが可能になった
6.わずか数分で世界中にデプロイ
AWSなら容易に遠隔地のリージョンにサーバーを構築も、複数のリージョンにアプリケーションを容易に展開することが可能
2-3 クラウドアーキテクチャの設計原理
|
故障に備えた設計(Design for Failure)をすれば、何も故障しない Design for Faillure を実現するためには、単一障害点( single Point Of Failure、SPOF )をなくすることが必要 ・1つのデータセンターのみで運用しない ・単一のインスタンスのみで構成しない |
35頁 |
重要ポイント
・Design fot Failure = 単一障害点をなくそう
・マネージドなサービスを利用しよう。AWSのマネージドなサービスは単一障害点にならないように考慮されてている
|
コンポーネントの分離 システムのコンポーネントを疎結合にすればするほど、スケーリングが大規模にうまくいく |
36頁 |
● Amazon SQS ( Simple Queus Service )
キューイングチェーン(リンク)を利用して非同期かつ疎結合にすることが可能。キューには処理が完了されるまでデータが残っている為、万が一処理中のコンピューティングリソースに障害が起きたとしても、他のコンピューティングリソースが処理を継続できる為、耐障害性の確保に繋がる(図1)
● マイクロサービスアーキテクチャ(リンク)
システムを複数の小規模なサービスの集合体として構成し、コンポーネントの分離を促進することができる(図2)


重要ポイント
・システムのコンポーネントを疎結合にする ・マイクロサービスアーキテクチャーを利用する ・SQS、キューイングチェーンを利用して、非同期かつ疎結合な構成をとる
|
弾力性の実装 弾力性は伸縮性とも言い、リソースの性能を柔軟にスケールアウトしたり、スケールインすることが可能。弾力性は次の3つの方法を用いる |
37頁 |
● 巡回スケーリング
一定間隔(毎日、週ごと)に発生する定期的なスケーリング
● イベントベーススケーリング
イベントによる急激なトラフィック増加に備え実施するスケーリング。スケジュールドスケールアウトパターンで弾力性を実現(図1)
● オンデマンド自動スケーリング
監視サービスからのアラートをトリガーに行うスケーリング。スケールアウトパターンで弾力性を実現(図2)
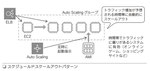
重要ポイント
・固定されたリソースでなく、クラウドの利点である弾力性(伸縮性)を使って動的にスケーリングを行う ・使い捨て可能なリソースとして、サーバーを考える
|
並列化を考慮する クラウドでは繰り返し可能なプロセスを極めて容易に構築できるため、できるだけ並列化を実施し、さらに可能であれば自動化することを推奨 |
39頁 |
重要ポイント
・ロードバランサーを組み合わせて、並列処理を行う ・スケーリングは弾力性を組み合わせて、高負荷時にスケールアウト、低負荷時にはスケールインを行う
|
動的コンテンツデータをコンピュータの近くに 例えば、データウェアハウスアプリケーションの場合、データセットをクラウドに移行し、次にデータセットに対して並列クエリを実行することが望ましい。
|
40頁 |
重要ポイント
・静的コンテンツは外部に出して、エンドユーザの近くに保管する ・動的に処理するデータは、クラウド上のコンピューティングリソースの近くに保管する
2-4 AWS Well-Architected フレームワーク
|
AWSによる優れた設計のフレームワークとは、信頼性、セキュリティ、効率、コスト効果が高いシステムを設計しクラウドで運用するために作られたアーキテクチャのベストプラクティス。以下はAWS Well-Architectedフレームワークの5本柱 |
42頁 |
1.運用上の優秀性
プロセスと手順を継続的に改善する機能
2・セキュリティ
情報、システム、資産を保護する
3.信頼性
インフラストラクチャやサービスの障害からの復旧
4.パフォーマンス効率
コンピューティングリソースを効率的に使用し維持する
5.コスト最適化
最も安価にシステムを実行する能力
❏第3章 AWS セキュリティ
3-1 AWSの責任共有モデル
|
AWSとユーザが責任を負う部分が明確に分かれ、それぞれがセキュリティを共有して守っていくことをAWS責任共有モデルと呼ぶ マネージドなサービスを利用することでAWSがマネージしてくれる部分はユーザーの責任範囲からAWSの責任範囲へと移管される(図) |
47頁 |

1.クラウド本体のセキュリティ(AWSの担当)
- リージョン、アベイラビリティゾーン、エッジロケーションといったデータセンターの地域
- マネージドなサービスのソフトウェアおよび、それに含まれる各種サービスの管理(アップデートやセキュリティパッチのインストール)
2.クラウド内のセキュリティ(ユーザーの担当)
- ゲストOSの管理(アップデートやセキュリティパッチのインストール)
- 関連アプリケーションソフトウェアの管理
- AWS提供のセキュリティグループファイアウォールの設定
● アベイラビリティゾーン
AWSの各リージョンに存在するデータセンター。 各リージョンには複数のアベイラビリティゾーンが存在しており、それぞれにAmazon EC2などを配置することで、地理冗長化を簡単に行うことができる
● エッジロケーション
Amazon CloudFrontサービス(コンテンツ配信ネットワーク(CDN))を提供
重要ポイント
・AWSはクラウド本体のセキュリティ部分を担当する ・ユーザーはクラウド内のセキュリティを担当する ・AWSが用意するセキュリティサービスを適切に活用して、ユーザーはクラウド内のセキュリティを管理できる
3-2 AWSクラウドのセキュリティ
|
AWSが責任を持つ範囲の考え方 |
49頁 |
◆ 物理的なセキュリティ
データセンターの外側のレイヤーの解説
| 1.環境レイアー | AWSの各リージョンにおけるデータセンター群は、互いに独立し物理的に分離されているため、自然災害が特定のデータセンター群に影響を与えたとしても、処理中のトラフィックを影響のある地域から自動的に移動できる |
| 2.物理的な境界防御レイアー | レイヤーはいくつもの特徴的なセキュリティ要素を含んでおり、物理的な位置によって、保安要員、防御壁、侵入検知テクノロジー、監視カメラ、その他セキュリティ上の装置などが存在する |
| 3.インフラストラクチャレイアー | 発電設備、冷暖房換気空調設備、消火設備などといった機器や設備はサーバーを保護するために重要な働きをする |
| 4.データレイヤー | ユーザーのデータに対してアクセスを制御し、各レイヤーにおいて特権を分離する |
◆ ハイパーバイザーセキュリティ管理
VMエスケープやクラウドバーストVMエスケープ、VMホッピングなどのハイパーバイザーをターゲットとした各種攻撃に関してはAWSが対応。プロセッサの重大な脆弱性もAWSハイパーバイザー上で解決してる。準仮想化(PV)インスタンスに関しても最新のAMIのイメージの提供や更新パッケージを提供している
重要ポイント
・AWSのデータセンターのセキュリティはAWSの担当 ・ハイパーバイザーのセキュリティはAWSの担当
◆ 管理プレートの保護
管理プレーンの保護に関するセキュリティの範囲はユーザーの担当。管理プレーンとしては、具体的に以下のものが挙げられる
| IDとパスワード | パスワードが流出したことによりユーザーの意図しないクラウドの利用が行われ請求が発生した場合はユーザーの過失。AWSサインアップ時に作成したルートアカウントなど、権限の強いアカウントにはMFAなどを設定しアカウントの保護を行うようにする(図1) |
| ルートアカウント | AWSサインアップ時に作成したメールアドレスのアカウントをルートアカウントという。ルートアカウントは全ての操作をすることが出来る、ユーザーが利用する最も権限の強いアカウント |
| キーペアの管理 |
キーペアは、EC2などのインスタンスへのログインで利用する。現在ではセキュリティを高めるため、公開鍵認証方式を用いてキーペアによってログイン認証を行うのが一般的。キーペアの秘密鍵の管理はユーザーの責任(図2) |
| APIキーの管理 |
各ユーザーは、アクセスキーとシークレットアクセスキーを作成・保持する。このペアをコマンドライン(AWS CLI)操作や、プログラム(AWS SDK)の認証情報として利用する。アクセスキーとシークレットアクセスキーの値を環境変数や認証ファイル内に格納して利用する。権限の強いアカウントからAPIキーを生成せず、そのCLIやプログラムで利用する範囲の権限のみに付与する。現在はAPIキーの利用は推奨されておらずIAMロール(詳細は後述)の利用が推奨されている |
重要ポイント
・管理プレートの保護はユーザーの担当 ・IDとパスワードはユーザーが適切に管理する。権限の強いアカウントにはMFAを組み合わせて利用する ・キーペアはユーザーが適切に管理する ・APIキーはユーザーが適切に管理する。必要最低限の権限のみを付与する ・ルートアカウントのAPIキーは作成しない

◆ マネージドでないサービスのセキュリティ
Amazon EC2 や Amazon VPC など、Infrastructure as a Service(IaaS)のカテゴリに分類されるAWSサービスは、ユーザーがadministrator権限やroot権限を持ちすべてを管理するため、ユーザーは必要なセキュリティ設定と管理タスクをすべて実行する必要がある
重要ポイント
・マネージドでないサービスのセキュリティの責任について、ユーザーが操作できる部分はすべてユーザーの責任 ・ユーザーが操作できるマネージドでない部分は、オンプレミスのシステムで行ってきたことと同様 ・Amazon EC2などのコンピューティングサービスは、OS層以上はユーザーの責任 ・ファイアウォール(セキュリティグループ)の設定内容は、ユーザーの責任
◆ マネージドなサービスのセキュリティ
重要ポイント
・マネージドなサービスの責任は、ユーザーとAWSでそれぞれが分担
・サービスのプラットフォーム部分はAWSの責任
・サービスのプラットフォーム上のデータや、その上に置くアプリケーションはユーザーの責任
・サービスにアクセスするためのアクセスコントロール設定とアカウント認証情報の保護は、ユーザーの責任
・マネージドでないサービスより、ユーザーのセキュリティに関する負担は軽減
|
セキュリティのベストプラクティス 下記4点はユーザーの責任 |
56頁 |
1.転送中データの保護
第三者から通信内容を秘匿する必要があることから、適切なプロトコルおよび暗号化アルゴリズムを選択する
2.蓄積データの保護
蓄積データの物理的な保護はAWSが行う。データベースへの接続時にアプリケーション上でデータの暗号化を行うことが望ましい。そのシステムのコンプライアンス上の要件に応じて、データの暗号化を行うことはユーザーの担当
3.AWS資格情報の保護
ルートアカウントを使用せず、ユーザーごとにIAMユーザーを作成し、必要な最低限の権限を付与する
4.アプリケーションの安全性の確保
実行するアプリケーションの安全性を確保するためには、既知の攻撃に対する対応を行う。脆弱性関連情報をチェックし、Amazon Inspectorなどを活用し、定期的な脆弱性診断を行うことが望ましい
重要ポイント
・転送中データを保護するには、適正なプロトコルおよび暗号化アルゴルズムを選択する ・蓄積データーを保護するには、コンプライアンス要件に従い暗号化を行う。AWSの提供する暗号化オプションを活用する ・AWS資格情報を保護するには、適切なユーザーの作成と、必要最低限の権限設定を行う ・アプリケーションの安全性を確保するには、定期的な脆弱性診断と脆弱性情報の確認、アプリケーションの改善を行う
|
第三者認証 AWSは、コンピュータのセキュリティに関する様々な規格や規制に準拠しているかどうかについて、第三者の監査機関による検査を受けている。そのレポートをユーザーにAWS Artifactにて提供している。AWS Artifactは、無料でセルフサービス型の、AWSコンプライアンスレポートのダウンロードサービス。ISO、PCI、SOCなどの第三者による監査レポートをダウンロードできる(図1、2) |
57頁 |


3-3 IAM
|
IAM(AWS Identity and Access Management)は、ユーザーのAWSクラウドリソースへのアクセス管理サービス。IAMにより、 AWSのユーザーとグループを作成および管理し、アクセス権を使用してAWSリソースへのアクセスを許可あるいは拒否できる |
59頁 |
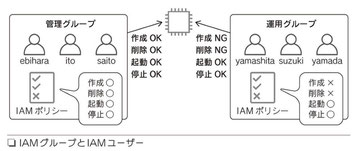
IAMでは、AWSアカウント内にIAMユーザーやIAMグループを作成することができる(図)
IAMユーザーごとに、AWSの各種リソースに対するアクセス権を設定でき、IAMユーザーに対してAPIキーも作成できる
IAMロール
現在APIキーの利用は推奨されていない。これに代わってIAMロールを利用する。AWSの内部でIAMロールとEC2を直接紐づけることが出来るため、キーを管理する必要がなくなる
重要ポイント
・各IAMユーザー、IAMグループには、必要最低限の権限を付与する ・IAMポリシーが相反するときは、拒否が優先される ・IAMユーザーには、最大2つのAPIキーが発行できる
3-4 セキュリティグループ
|
オンプレミスでは中央集権的なファイアウォールを1つ、外部ネットワークの前に設定していたのに対して、AWSでは、各インスタンス毎に個別のファイアウォール設定を行えるセキュリティグループという機能がある。同一の目的で利用するサーバー群に対して同一の設定を適用することも可能(図) |
61頁 |

- 許可ルールの指定が可能
- 拒否ルールの指定は不可能
- インバウンドトラフィックとアウトバウンドトラフィックのルールを個別に指定可能
Column
|
個人情報漏洩保険
|
62頁 |
3-5 AWS Shield と AWS WAF
|
AWS Shield |
63頁 |
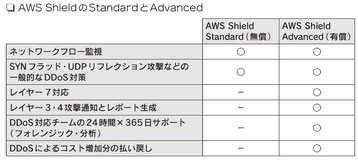
AWS Sheildは、マネージド型の分散サービス妨害(DDos攻撃)に対して、
AWSで実行しているWebアプリケーションを保護してくれる
AWS Sheildは、アプリケーションのダウンタイムとレイテンシーを最小限に
抑える常時稼働の検出と自動インフラ緩和策を提供している
AWS Sheildには「Standard」と「Advanced」の2種類のサービスがある(図)
すべてのAWSのユーザーは、追加料金なしでAWS Sheild Standardの保護の
適用を自動的に受けることができる
重要ポイント
・各IAMユーザー、IAMグループには、必要最低限の権限を付与する ・AWS Sheildはマネージド型のDDos攻撃に対する保護サービス ・AWS Sheild Standardは一般的なDDos攻撃からAWS上のシステムを保護する ・AWS Sheild Advancedは、Standardに加えて、DDos Respones Teamによる緩和策を実施し、攻撃を可視化する ・AWS Sheild Advancedでは、AWS WAFが無償で無制限に利用可能
|
AWS WAF Webサイト上のアプリケーションに特化したファイアウォール。主に、ユーザーからの入力を受け付けたり、リクエストンに応じて動的なページを生成したりするタイプのWebサイトを不正な攻撃から守る役割をはたす。一般的なファイアウォールと異なり、データの中身をアプリケーションレベルで解析できるのが特徴
どのトラフィックをWebアプリケーションに許可、またはブロックするかのWAFの定義をユーザー自身で行う必要がある。SQLインジェクションまたはクロスサイトスクリプトのような一般的な攻撃パターンをブロックするカスタムルール、および特定のアプリケーションのために設計されるルールをAWS WAFに作成できる
|
66頁 |
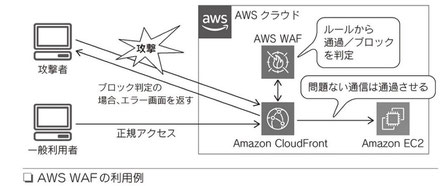
課金はユーザーが作成するカスタマイズ可能なWebセキュリティルールの
指定に基づいて行われる
- Webアクセスコントロールリスト(Web ACL)数に基づく課金方法
- Web ACLごとに追加するルール数に基づく課金方法
- 受け取るWebリクエスト数に基づく課金方法
◆ AWS WAFの適用範囲
Web ACLでのAWS WAFの適用サービスは以下から選択する(図)
- CDNサービスのCloudFront
- ロードバランサーのApplication Load Balancer
- API Gateway(APIの管理や実行を容易にするしくみ)
重要ポイント
・AWS WAFはマネージド型のWebアプリケーションファイアウォールサービス ・AWS WAFの基本利用料は無料。Webセキュリティルールに基づき課金される ・AWS WAFのWebセキュリティルールはユーザーが設定する必要がある ・Web ACLの適用サービスは、CloudFront、Application Load Balancer、API Getewayから選択する
3-6 Inspector
|
Inspector AWSのEC2上にデプロイされたアプリケーションのセキュリティとコンプライアンスを向上させるための、脆弱性診断を自動で行うことができるサービス。評価が実行された後、重大性の順に結果を表示した詳細なリストがInspectorによって作成される
◆ AWS Artifact AWSのコンプライアンスレポートをオンデマンドでアクセスできる無料のセルフサービスポータル
◆ AWS Key Management Service(KMS) AWS上で暗号化キーを簡単に作成・管理し、幅広いAWSのサービスやアプリケーションでの使用を制御できるサービス |
68頁 |
重要ポイント
・Amazon Inspectorは脆弱性診断を自動で行うことができるサービス ・EC2上にデプロイされたアプリケーションに対応 ・各種ルールパッケージはAWSが最新のものにアップデート ・スケジューリング設定により、完全に自動でチェック可能 ・AWSのコンプライアンスレポートを取得するにはAWS Artifactからダウンロードする ・AWS Key Management Service(KMS)は、AWS上で暗号化のためのキーを作成・管理し、暗号化の制御が行えるサービス
❏第4章 AWS のテクノロジー
4-1 AWSのサービス
|
AWSには現在180を超えるサービスがある。AWSではこれらのサービスから必要なものを選択して繋ぎ合わせることでシステムを構築する |
75頁 |
|
AWSサービスのカテゴリー AWSの各サービスは主に以下のカテゴリーに分けられる(図) |


|
AWSサービスをどこで使うのか
|
76頁 |
4-2 グローバルインフラストラクチャ
|
AWSが提供しているグローバルインフラストラクチャは、リージョンとアベイラビリティゾーンを中心に提供されている |
77頁 |
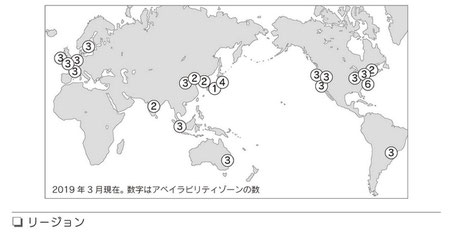
リージョン
AWSには、全世界に現在(2020年5月)24個のリージョン(図)と
1つのローカルリージョンがある。日本には「東京」リージョンがある
リージョン内には2つ以上のアベイラビリティゾーンがある
要件に応じて、システムを構築するリージョンを選択する
◆ リージョンの選択
リージョンは以下の条件に基づいて選択する
- 保存するデータやシステムがそのリージョン地域の法律やシステムを所有している企業のガバナンス要件を満たしているか
- ユーザーや連携するデータに近いか
- 必要なサービスが揃っているか
- コスト効率が良いか
重要ポイント
・全世界に展開されているリージョンを選択して、数分で世界中にシステムをデプロイできる ・リージョンによって利用できるサービス、コストが異なる

アベイラビリティゾーン
各リージョンはアベイラビリティゾーン(AZ)(図)が2つ以上ある
複数のデータセンターからアベイラビリティゾーンが構成されている
◆ なぜアベイラビリティゾーンは2つ以上あるのか
アベイラビリティゾーンを複数使うことで、耐障害性の高いシステムを構築することができる。サーバーなどのコンポーネント単位で、負荷分散、レプリケーション、冗長化を実装し、障害が発生した際には自動的にフェイルオーバーできるようなアーキテクチャを簡単に実装できるサービスや機能が提供されている
◆ AWSのデータセンター
アベイラビリティゾーンは複数のデータセンターで構成されている。場所は非公開で、一見ではデータセンターとは分からない施設となっている。警備員の配置、監視カメラ、侵入検知テクノロジー、防護壁、多要素認証などにより、物理的に厳重に保護されている
重要ポイント
・リージョンにはアベイラビリティゾーンが2つ以上ある(ローカルリージョンを除く) ・アベイラビリティゾーンは障害が同時に影響しないよう、地理的に十分離れた場所にある ・同一リージョン内のアベイラビリティゾーン同士は高速なプライベート光ファイバーネットワーキングで接続されている ・複数のアベイラビリティゾーンを使うことで、耐障害性、可用性の高いアーキテクチャを実装できる ・データセンターは、セキュリティ、コンプライアンス上の様々な第三者監査検証を実施している
|
エッジロケーション AWSには、リージョンとは違う場所に、全世界で現在200か所以上のエッジロケーションがある。 |
81頁 |
◆ 低レイテンシーなDNSクエリの実現
DNSサービスであるAmzon Route 53がエッジロケーションで利用されている。ユーザーに対して最も低レイテンシーのエッジロケーションからDSNクエリの結果を返すことができる
◆ コンテンツの低レイテンシー配信
CDNサービスであるAmzon CloudFrontがエッジロケーションで利用される。ユーザーに対して最も低レイテンシーのエッジロケーションからコンテンツキャッシュを配信することができる
◆ エッジロケーションの分散サービス妨害攻撃からほ保護
Route 53とCloudFrontは、分散サービス妨害(DDo攻撃)に対する保護サービス(AWS Shield Standard)の対象
◆ 多様な選択肢
さらに、さまざまな選択肢が提供されている
- AWS Local Zones(エンドユーザーからより近い場所に配置)
- AWS Wavelength(アプリケーションに10ミリ秒未満のレイテンシーを実現)
- AWS Outposts(オンプレミス施設でAWSサービスを利用)
重要ポイント
・リージョンとは違う場所に200以上のエッジロケーションがある ・エッジロケーションではAmazon Route 53とAmazon CloudFrontを利用できる ・ユーザーは最も低レイテンシーのエッジロケーションにアクセスできる ・Amazon Route 53 と Amazon CloudFront は AWS Sheild により DDos攻撃から保護される
❏第5章 コンピューティングサービス
5-1 EC2
|
EC2の概念 EC2はAmazon Elastic Compute Cloudの略で、頭文字がEと2つのCなのでEC2と呼ばれる。AWSのサービスでは「Elastic」という言葉が多く出てくる。これは「弾力性がある」「伸縮自在な」という意味 |
89頁 |
|
EC2の特徴 |
89頁 |
◆ 必要なときに必要なだけの量を使用
重要ポイント
・使う時にだけEC2インスタンスを起動することができる ・必要なEC2インスタンスの数を事前に予測する必要はない
◆ 使用した分にだけコストが発生
EC2の料金は次の3種類から構成される
|
1.EC2稼働に対しての料金 OS,リージョン、インスタンスによって料金が異なる。この料金が1時間単位で課金される。Amazon Linux、Ubuntuでは1秒単位の課金。 EC2インスタンスが起動中の時間が課金対象となり、停止中は課金が停止される |
|
2.データ転送料金 リージョンの外にデータを転送した場合に、データ転送料金が発生する。データ転送料金はリージョンによって異なる。 インターネットからAmzon EC2へのデータ転送受信(イン)には課金されない |
|
3.ストレージ料金 厳密にはEC2の料金ではなく、EBS(Amazon Elastic Block Store。EC2 にアタッチ可能なブロックレベルのストレージサービス)の料金。 EBSに対しての課金は、1GBあたりの、プロビジョニング(図1)した料金。 |
重要ポイント
・使った分にだけ料金が発生する ・時間単位、秒単位で課金される ・アウト通信に転送料金が発生する
◆ 変更可能なインスタンスタイプから性能を選択
最初に決めたものをそのまま使い続けるのではなく、使い始めてから他のインスタンスタイプに変更することができる
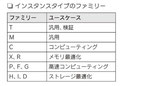
インスタンスタイプの表記(図2、3)
|
1.ファミリ EC2インスタンスを何に使用するか、用途(ユースケース)によって選択する |
|
2.世代 バージョン。 |
|
3.サイズ 性能のレベルを表す |
|
4.インスタンスタイプの選び方 必要としているコンピューティング処理が最も早く完了するインスタンスタイプを選択することがベストプラクティス |


重要ポイント
・インスタンスタイプは運用を開始した後に柔軟に性能を変更できる ・運用を開始する前の、誤った性能予測の計算をする必要がなくなる
◆ 数分でサーバーを調達して起動できる
一度に複数台を自動で起動できる。あらかじめ設定しておくことで、調達、起動を自動化することもできる
重要ポイント
・数分でEC2を起動できることは、経営の俊敏性が増すことに直結する
◆ 世界中のリージョンから起動場所を選択
EC2を起動する場所を世界中のリージョンから選択できる。どこのリージョンでインスタンスを起動しても時間の差はない
重要ポイント
・数分でEC2を世界中にデプロイできる
◆ AMIからいくつも同じサーバーを起動できる
EC2インスタンスはAMI(Amazon Machine Image)から起動する。AMIはEC2インスタンスのテンプレートであり、オペレーティングシステム、アプリケーション、データなど様々な情報をEC2に提供する
AMIは大きく分けて4種類ある
|
1.クリックスタートAMI AWSがあらかじめ用意しているAMI。Amazon Linux、Windows、Ret hatなどのOSとモジュールがインストール済みで用意されている |
|
2.マイAMI お客様が作成するAMI。起動中のEC2を選択してイメージを作成する。マイAMIは他のアカウントと共有することも、公開することも可能 |
|
3.AWS Marketplace ソフトウェアやミドルウェアがすでにインストールされている構成済みのパートナーベンダーが提供しているAMI。ソフトウェアは提供ベ ンダーによってテスト済みの状態で提供される。ソフトウェアによっては、ライセンス料金が、EC2の従量課金に加算されるものもある |
|
4.コミュニティAMI 一般公開されているAMI。クイックスタート、マイAMI、Marketplaceに適したAMIがない場合はコミュニティAMIから選択する |
重要ポイント
・AMIから同じ構成のEC2インスタンスを何台でも起動できる ・AWS Marketplaceから簡単にソフトウェア構成済みのEC2インスタンスを起動できる
◆ オペレーティングシステムを管理者権限で操作できる
起動したEC2では、キーペアを使用してログインすることで、オペレーティングシステムを管理者権限で操作できる
重要ポイント
・オペレーティングシステムの管理者はキーペアで安全にログインできる
◆ ユースケースに応じた料金オプション
EC2インスタンスの使用料金にはいくつか料金オプションが用意されている。この料金オプションをユースケースに応じて使い分けることで、
お客様はコスト効率良くEC2を使用できる
|
● オンデマンドインスタンス 料金オプションを使わずにEC2インスタンスを起動すると、オンデマンドインスタンスの単価が適用される(定価料金)。秒単位、時間単位の課金により、必要なときに必要なインスタンスを起動できる。運用を開始してすぐのタイミングなど、インスタンスタイプの変更が必要な場合はオンデマンドインスタンスを使用 |
|
● リザーブドインスタンス 1年または3年の使用期間を事前設定することで、割引を受けることができる料金。3年・全額払いが最も割引率が高い選択(図1) |
|
● スポットインスタンス(図2,3) 市場取引の変動のように、未使用のEC2キャパシティの量が多いときはスポット料金が下がり、少ないときは上がる。このスポットインスタンスに対して支払っても良い金額をリクエスト料金という。スポット料金がリクエスト料金を下回るとスポットインスタンスは起動し、上回るとAWSによって終了される。処理途中で終了しても問題ないユースケースに向いている |
|
● Dedicated Hosts EC2 インスタンスを起動できるお客様専用の物理サーバー |
|
● ハードウェア専有インスタンス アカウント専用のハードウェアでEC2を実行。Dedicated Hostsとは違いインスタンス単位で料金が発生。専有追加料金が必要 |
|
● Savings Plans 1 年または 3 年の期間に特定の量の処理能力 (USD/時間で測定) を使用する契約を結ぶことにより、オンデマンドに比べて大幅に節約できます |


重要ポイント
・ユースケースに応じて料金オプションを使い分けることでコスト効率が向上する
|
EC2インスタンスの起動 |
109頁 |
- マネージメントコンソールにサイン
- サービスからEC2を選択してEC2のダッシュボードにアクセス
リージョンは東京になっている。起動中のインスタンス、サービスの状況やイベントが表示されている - [ インスタンスの作成 ] ボタンからインスタンスの起動を始める
- AMIを選択(図1:ステップ1 Amazonマシンイメージ(AMI))
クイックスタート、マイAMI、AWS Marketplace、コミュニティAMIから選択できる - インスタンスタイプを選択(図2:ステップ2 インスタンスタイプの選択)
vCPU、メモリー、選択でできるストレージ、ストレージの最適化有無、ネットワーク性能がインスタンスタイプごとに異なる - ネットワークの選択などを行う(図3:ステップ3 インスタンスの詳細の設定)
[ インスタンス数 ] に数字を入力すると、現在設定中の構成を持ったインスタンスを複数台同時に起動することができる
[ スポットインスタンスのリクエスト ] を有効にすると、起動するインスタンスをスポットインスタンスで起動することができる
ネットワークはVPCがデフォルト - ストレージボリュームの設定を行う(図4:ステップ4 ストレージの追加)
ストレージサイズは8GBがデフォルト - タグの設定(図5:ステップ5 タグの追加)
EC2インスタンスをユーザーやプログラムから見分けやすくするためのキーと値を設定できる - セキュリティグループの設定
SSHのポート番号を設定(図6:ステップ6 セキュリティグループの設定) - 確認画面の内容を確認(図7:ステップ7 インスタンス作成の確認)
問題なければ[ 作成 ] ボタンを選択 - キーペア選択画面が表示される
既存のキーペアを選択するか、新たなキーペアを作成することができる
[ インスタンスの作成 ] ボタンを押下するとrunning(起動中)の状態になる(図8、9) - 先ほど作成してダウンロードした秘密鍵を使ってSSHログインする(図10)







重要ポイント
・数クリック、数分でEC2インスタンスを起動できる
5-2 ELB
|
ELBの概要
|
115頁 |
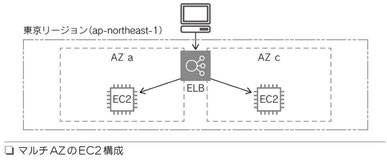
Elastic Load Balancingの略。ELBを使用することで、同じ構成を持つ2つのEC2インスタンスを別々のAZに配置することができる。そしてELBはその2つのEC2インスタンスに、ユーザーからのリクエストトラフィックを分散する(図)
重要ポイント
・EC2インスタンスの可能性を高めるためELBを使用することができる
|
ELBの特徴 |
117頁 |
◆ ロードバランサータイプ
ELBには3つのタイプがある
|
1.Application Load Balancer HTTP/HTTPSのリクエストを負荷分散する用途で選択する |
|
2.Network Load Balancer HTTP/HTTPS以外のTCPプロトコルを使用する場合に選択する |
|
3.Classic Load Balancer 以前のタイプのロードバランサー。以前の構成との互換性のために残されている |
重要ポイント
・HTTP/HTTPSではApplication Load Balancerを使い、それ以外のTCPではNetwork Load Balancerを使う
◆ ヘルスチェック
ヘルスチェックは、対象として指定されたパス(index.html)への簡単な接続試行、またはインスタンスに対してのpingで確認する
重要ポイント
・ELBには、正常なインスタンスのみにトラフィックを送るためのヘルスチェック機能がある
◆ インターネット向け/内部向け
ELBはインターネット向けに作ることも、内部向けに作ることもできる。作成するときにどちら向けかを選択する(図1)
ELBを作成すると、設定したELBの名前を含んだDNS名が付与される(図2)
このDNS名にパブリックIPアドレスが紐付くか、プライベートIPアドレスが紐付くかの選択によって設定結果が変わる
重要ポイント
・ELBはインターネット向けにも内部向けにも対応している
・インターネット向けだけでなく内部にもELBを挟むことによって、システムの可用性をさらに高めることができる

◆ 高可用性のマネージドサービス
内部的にはELBのノードと呼ばれるインスタンスが複数起動して、ユーザーからのリクエストを受け付けて負荷分散する。ELBを通過するトラフィックが増えれば自動的・水平的にこのELBのノードも増えてリクエストに対応する。なので、ELBは単一障害点にはならない(図)
重要ポイント
・ELB自体が高可用性のマネージドサービスなので
単一障害点とはならない
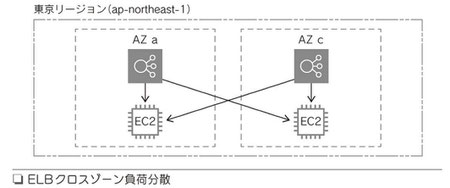
◆ クロスゾーン負荷分散
ELBのノードが存在するアベイラビリティゾーンだけではなく、他のアベイラビリティゾーンにも負荷分散ができる。これにより全ターゲットインスタンスで負荷を均等にできる(図)
重要ポイント
・複数のアベイラビリティゾーンに負荷分散を実行できる
のでリソースの負荷が均等になる
5-3 Auto Scaling
|
Auto Scalingの概念 |
124頁 |
必要なタイミングで必要なインスタンス数を柔軟に用意することができる。需要に応じて必要なインスタンスだけが起動しているということは、EC2インスタンスが最もコスト効率良く使われる
重要ポイント
・Auto ScalingによってEC2インスタンスを必要なときに自動で増減できる
・Auto Scalingのメリットは、高可用性・耐障害性・コスト効率化
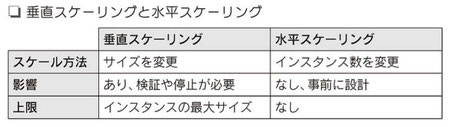
垂直スケーリングと水平スケーリング
垂直スケーリングでは、インスタンスのサイズを変更することによって、スケールアップ/スケールダウンを行う
水平スケーリングでは、インスタンス数を変更することによって、
スケールアウト/スケールインを行う(図)
重要ポイント
・垂直スケーリングよりも水平スケーリングのほうが
スケーラビリティを確保しやすい
|
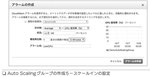
Auto Scalingの設定 Auto Scalingを実現するためには3つの要素を設定する。「何を」「どこで」「いつ」 |
127頁 |
◆ 起動設定(何を)
どの様なEC2インスタンスを起動するのかあらかじめ設定しておくのが起動設定。起動設定の他に起動テンプレートを使用することもできる
起動設定では以下を設定する(図1)
- AMI
- インスタンスタイプ
- IAMロール
- ユーザーデータ
- ストレージ
- セキュリティグループ
- キーペア
◆ Auto Scalingグループ(どこで)
アベイラビリティゾーンとVPCのサブネットを選択する。Auto Scalingグループでは以下を設定する(図2)
- 起動設定名
- アベイラビリティゾーン(サブネット)
- ELBのターゲットグループ
- 最小/最大/希望するインスタンス数
- 通知
- タグ
◆ Auto Scalingポリシー(いつ)
Auto Scalingポリシーには3タイプある
|
● ターゲットポリシー Auto ScalingグループのEC2インスタンス平均CPU使用率などを決めておくことで、AWSが最小数と最大数の間でEC2インスタンスを調整 最も簡単な設定方法(図3) |
|
● シンプルポリシー CloudWatchのアラームに基づいて、Auto Scalingアクションを実行する。「その後待機」はクールダウンと呼ばれる機能(図4) |
|
● ステップポリシー 複数段階でのインスタンスの追加、削除を設定できる(図5) |
さらに、Auto Scalingアクションはポリシーだけでなく、時間を指定したスケジュールでも実行できる。スケジュールで設定できる情報は、最小数、最大数、希望数(図6)





重要ポイント
・Auto Scalingでは起動設定(何を)、Auto Scalingグループ(どこで)、スケーリングポリシー(いつ)を設定する
|
アプリケーションデプロイの自動化 |
131頁 |
Auto Scalingによって、AMIを基に起動したインスタンスの起動時にコマンドスクリプトを実行して、たとえばソースコードを最新にできる。EC2には初回起動時に自動実行してデプロイを自動化できるユーザーデータという機能がある。もしもユーザーデータの処理の中でインスタンス固有の情報が必要な
場合は、メタデータを利用する
重要ポイント
・EC2のユーザーデータを使うことでコマンドを自動実行し、デプロイ処理を自動化することができる
・EC2の情報(IPアドレスやインスタンスID)はメタデータから取得できる

|
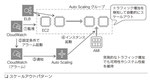
ELBとAuto Scalingを使用したスケーラブルなWebアプリケーション |
133頁 |
ELBのAplication Load BalancerとAmazon CloudWatchのアラーム、
それにAuto Scalingを使ったスケーラブルなWebアプリケーションを構築(図)
◆ Application Load Balancerの作成
| 1.マネージメントコントロールでEC2を選択 |
| 2.EC2ダッシュボードで左ペインからロードバランサーを選択 |
| 3.[ロードバランサーの作成] をクリック(図1) |
|
4.ロードバランサーの種類にApplication Load Balancerを選択(図2) |
|
5.ステップ1:ロードバランサーの設定(図3)
・ロードバランサー名「DemoELB」 ・ステップ1:ロードバランサーの設定ではAZを2箇所選択 subnet-46a8b21d - ap-northeast-1c subnet-5fdf7417 - ap-northeast-1a |
|
6.ステップ2:セキュリティ設定の構成では、SSLの証明書の設定を行う(今回は検証なのでこの設定は行わない)(図4) |
|
7.ステップ3:セキュリティグループの設定では、既存のセキュリティグループを選択する(図5) ・「新しいセキュリティグループを作成する」を選択して以下を作成。セキュリティグループ「load-balancer-wizard-1」 ------------------------------------------------------------------------------------------------ [タイプ] [プロトコル] [ポート範囲] [ソース] HTTP TCP 80 カスタム、0.0.0.0/0, ::/0 SSH TCP 22 カスタム、0.0.0.0/0 |
|
8.ステップ4:ルーティングの設定(図6)
|
|
9.ステップ5:ターゲットの登録。設定の確認画面で問題なければそのまま作成する(図7) |







◆ 起動設定の作成
Auto Scalingでどのようなインスタンスを起動させるかを設定
|
1.EC2ダッシュボードで左ペインから起動設定を選択し、[起動設定の作成] をクリック(図8) ・起動設定名「DemoAutoScaling」 |
| 2.AMIの選択 ー 今回はAmazon Linux 2を選択(図9) |
| 3.インスタンスタイプの選択 ー 静的HTMLが1ページならt2.nanoで十分。無料利用期間中ならt2.microを選択(図10) |
|
4.詳細設定(図11)
・▶高度な詳細 > ユーザーデータ で「テキストで」を選択して以下を記載 #!/bin/bash -ex
yum -y update
yum -y install httpd
systemctl start httpd.service
systemctl enable httpd.service
AZ=`curl --silent http://169.254.169.254/latest/meta-data/placement/availability-zone`
INSTANCE_ID=`curl --silent http://169.254.169.254/latest/meta-data/instance-id`
IP_ADDRESS=`curl --silent http://169.254.169.254/latest/meta-data/public-ipv4`
echo $AZ >> /var/www/html/index.html
echo $INSTANCE_ID >> /var/www/html/index.html
echo $IP_ADDRESS >> /var/www/html/index.html
|
|
5.ストレージの追加 ー デフォルトの8GBのままで設定(図12) |
|
6.セキュリティグループの設定(図13、14)
|
|
7.[この起動設定を使用してAuto Scalingグループを作成] ボタンをクリック(図15) ・参考書の「この起動設定を使用してAuto Scalingグループを作成する」ボタンは無かったので、「起動設定の作成」ボタンを押下 |
|
8.引き続きAuto Scalingグループを作成 ・起動設定一覧で作成した起動設定を選択し「アクション▼」から「 Auto Scalingグループの作成」を選択。遷移先画面では起動設定 に作成した起動設定名が指定されていた。 |








◆ Auto Scalingグループの作成
EC2インスタンスをどこで起動するかの設定
|
1.Auto Scalingグループの詳細設定
|
|
2.スケーリングポリシーの設定(スケールアウト)
・参考には「スケーリングポリシーの設定」とあったが「グループサイズとスケーリングポリシーを設定する」に変更されている。 とりあえず「希望する容量=2、最小キャパシティ=2、最大キャパシティ=4」で設定。EC2インスタンスは2台生成された。 ・スケーリングポリシー - 省略可能では、メトリクスタイプ:平均CPU使用率、ターゲット値:60、ウォームアップする秒数:60、
「スケールインを無効にしてスケールアウトポリシーのみを作成する」をOFFのままに設定 ・インスタンスのスケールイン保護 - 省略可能では、「インスタンスのスケールイン保護を有効にする」をOFFのままにした |
|
3.スケーリングポリシーの設定(スケールイン)
・スケールインの詳細設定欄は見つからなかった |
|
4.通知の設定。Auto Scalingアクション実行時、通知することが可能。(図22) |
|
5.タグの設定(図23)
|
|
6.確認。設定を確認して作成する(図24) |
|
ステップスケーリングの追加 【Auto Scaling グループの作成】※ここまでの手順と違うところを以下に明記 ・グループサイズは全て[1]のままにする ・スケーリングポリシー - 省略可能で「なし」を設定
・タグで「Name」キーに「Demo ASG Step」と設定 【CloudWatchアラートの作成】 1. CloudWatchで[アラームの作成]をクリック 2. [メトリクスの選択]をクリック 3. 名前空間から[EC2] > [Auto Scaling グループ別] をクリック 4. 標準メトリクスから[CPUUtilization]にチェックをいれ[メトリクスの選択]をクリック 5. メトリクス欄で以下を設定 ・メトリクス名:CPUUtilization ・AutoScalingGroupName:DemoAutoScalingGroup ・統計:平均値 ・期間:1分 6. 条件欄で以下を設定 ・しきい値の種類:静的 ・CPUUtilization が次の時...:より大きい ・... よりも:60 ・▶その他の設定 > アラームを実行するデータポイント:2/3 ・▶その他の設定 > 欠落データの処理:欠損データを見つかりませんとして処理 7. [次へ]をクリック 8. 通知欄でで以下を設定 ・アラーム状態トリガー:アラーム状態 ・SNSトピックの選択:既存の SNS トピックを選択 ・通知の送信先:Default_CloudWatch_Alarms_Topic 9. [次へ]をクリック 10. 名前と説明を追加欄で以下を設定 ・アラーム名「Demo Auto Scaling Alert」 ・アラームの説明 - オプション:未入力 11. [次へ]をクリック 12. [アラームの作成]をクリック
【ポリシーを追加】 1. Auto Scaling グループ一覧から選択して自動スケーリングタブで「ポリシーを追加」ボタンを押下 2. スケーリングポリシーを作成欄で以下を設定 ・ポリシータイプ:ステップスケーリング ・スケーリングポリシー名「Increase Group Size」 ・CloudWatchアラート:先に作成したアラート「Demo Auto Scaling Alert」を選択 ・アクションを実行で以下の様に設定 [1] 次のとき:[60] <= CPUUtilization < [80] [2] 次のとき: [80] <= CPUUtilization < +無限大 メトリクスに含める前にウォームアップする秒数:[10] 3. [作成]をクリック 4. 作成されたポリシーには以下のように表示される ポリシータイプ:ステップスケーリング アラームのしきい値を超過:次のメトリクスディメンションに対して 60 秒間の 3 連続期間で CPUUtilization > 60 アクションを実行: 60 <= CPUUtilization < 80 のときの 1 キャパシティユニットの 追加 80 <= CPUUtilization < +無限大 のときの 2 キャパシティユニットの 追加 インスタンスには以下のものが必要です:各ステップの後に 10 秒 秒間ウォームアップする |







◆ 動作確認
| 動作確認1 |
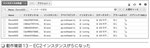
EC2インスタンスの一覧を見ると、DemoASGのタグが付いたEC2インスタンスが2つのアベイラビリティゾーンで1つずつ起動していることが確認できる(図25) EC2インスタンスの一覧を見ると、DemoASGのタグが付いたEC2インスタンスが2つのアベイラビリティゾーンで1つずつ起動していることが確認できた |
| 動作確認2 |
ELBのターゲットグループを見ると、2つのインスタンスが「healthy」ステータスになっていることが確認できる(図26) ELBのターゲットグループのターゲットタブを見ると、2つのインスタンスが「healthy」で有ることが確認できた |
| 動作確認3 |
Auto Scalingグループを見ると、インスタンス数が「2」になっている。そしてターゲットグループ同様に2つのインスタンスが「healthy」ヘルスステータスになっていることが確認できる(図27) Auto Scalingグループを見ると、インスタンス数が「2」で、インスタンス管理タブのインスタンス一覧はヘルスステータスが「healthy」だった |
| 動作確認4 |
ELBのDNS名をコピーしてブラウザのURLに入力してアクセスしてみる(図28) ELBのDNS名をコピーしてブラウザからアクセスできた |
| 動作確認5 |
EC2インスタンスにアクセスでき、アベイラビリティゾーン、インスタンスID、バプリックIPアドレスが表示される(「起動設定の作成-4.詳細設定-ユーザーデータの設定」によるもの)(図29) ブラウザに”ap-northeast-1a i-08b8fecea79f2cc05 18.179.14.136”と表示された”と表示された |
| 動作確認6 |
ブラウザ画面を更新すると、もう1つのインスタンスにリクエストが送信されて、アベイラビリティゾーン、インスタンスID、バプリックIPアドレスがかわったことが確認できる。つまり、負荷分散がされているということ(図30) ブラウザ画面を更新すると、もう1つのインスタンスにリクエストが送信され、"ap-northeast-1c i-0eb46bf556993a49f 54.249.12.198"と表示された |
| 動作確認7 |
CloudWatchのアラームを見てみると、2つのアラームが作成されいることが確認できる CPU使用率40%以下のアラームが「アラーム」の状態になっている(図31) CloudWatchの左側で「アラート」をクリック。2つのアラームが作成されいることが確認できた |
| 動作確認8 |
Auto Scalingで起動している2つのEC2インスタンスそれぞれにSSHでログインし、「$ yes > /dev/null」コマンドで負荷をかける。 CloudWatchのメトリクスを見ると、CPU使用率が上がっていくことが確認できる(図32) 「$ yes > /dev/null」実行。CloudWatchの左側で「メトリックス」を選択。「すべてのメトリックス」タブで「EC2 > Auto Scaling グループ別 > cpuutilization」の順に選択してCPU使用率のグラフを確認 |
| 動作確認9 |
CloudWatchのアラームを見ると、CPU使用率60%以上のアラームが「アラーム」の状態になる(図33) CloudWatchの左側で「アラート」では以下の状態だった ・3 分内の3データポイントのCPUUtilization > 60 :アラーム状態 ・15 分内の15データポイントのCPUUtilization < 45 :OK |
| 動作確認10 |
Auto Scalingグループを見ると、「希望するインスタンス数」と「インスタンス数」が「3」になっている(図34) しばらく経過してAuto Scalingグループを見ると、「希望する容量」と「インスタンス」が「4」になった |
| 動作確認11 |
実際に起動しているインスタンスも「3」になっている(図35) 実際に起動しているインスタンスも「4」になった |
| 動作確認12 |
このままにしていると平均CPU使用率が80%を超える(図36) 参考書のように2段階設定( Warning、Critical)ができなくなっている |
| 動作確認13 |
さらに2インスタンス追加のオートスケールアクションが実行されて、EC2インスタンスは「5」になる(図37) スキップした |
| 動作確認14 |
プロセスをkillすると平均CPU使用率がさがる(図38) プロセスをkillすると平均CPU使用率がさがった |
| 動作確認15 |
スケールインアクションによりEC2インスタンスが削除されたことを確認(図39) しばらく経過してスケールアウトした2台のEC2インスタンスがスケールインされたことを確認 |














重要ポイント
・ELB,CloudWatch、Auto Scalingの3つのサービスで、自動的でスケーラブルなアプリケーションを構築できる
5-4 Lambda(ラムダ)
|
Lambdaの特徴 |
150頁 |
◆ Lambdaの特徴
- サーバーの構築は不要
- サーバーの管理が不要
- 一般的な言語のサポート
- 並列処理/スケーリング
- 柔軟なリソース設定
- ミリ秒単位の無駄のない課金
- 他のAWSサービスとの連携
◆ サーバーの構築が不要
実行したいプログラムのランタイムを選択してソースコードをアップロードすれば、もう実行できる。オペレーティングシステムの用意、実行するためのミドルウェアのインストール、環境設定など、本来注力する必要のない作業をおこなわなくてすむ
Lambdaをマネージメントコンソールから作成する場合、名前を決め、ランタイムを選択し、権限をIAMロールから選択したら、後はソースコードをアップロードするだけ
重要ポイント
・サーバー構築や環境の準備をすることなく、すぐに開発を始められる
◆ サーバーの管理が不要
以下のようなサーバーの管理が不要になる
- オペレーティングシステムの更新
- セキュリティパッチの適用
- ディスク容量の追加
- オペレーティングシステム、ミドルウェアのメンテナンス
- 冗長化、障害時の復旧
- スケーラビリティの確保
- 障害を考慮した設計
- 実行エラー時のリトライ
- ジョブが特定時間に集中することへの配慮
重要ポイント
・サーバーの運用から解放され、開発に注力できる
◆ 一般的な言語のサポート
以下の言語であれば、そのコードを書くだけでLambdaを使える
- C#
- PowerShell
- Go
- Java
- Node.js
- Python
- Ruby
重要ポイント
・Lambdaを使うために新しい言語の勉強は不要。使い慣れた言語ですぐに始められる
◆ 平行処理/スケーリング
- Lambdaは、リクエストやトリガーからの実行指示がないときは実行されない
- 従来のサーバーのようにリクエストを待っている間に稼働し続けておく必要がない
- リクエストやトリガーによってコードが実行される
- もし2つのリクエストが同時に発生した場合は、2つのLambda関数が同時に実行される
- リクエストの数が増えれば、実行されるLambda関数の数も増える。初期設定の同時実行数は「1000」
重要ポイント
・リクエストに応じて水平的にスケーリングして、平行で関数が実行される
・Auto Scalingを設定する必要がない
◆ 柔軟なリソース
- Lambdaで設定する性能はメモリ。設定できる範囲は128MBから3008MBの間で、64MB刻みで設定できる
- CPU性能はメモリに比例して割り当てられる
- メモリの設定が課金に影響する
- タイムアウト時間は最長15分。Lambdaで実行できる処理は15分までということ
重要ポイント
・メモリを割り当てるとこで他のリソースの性能も割り当てられる
◆ ミリ秒単位の無駄のない課金
- コンピューティング料金とリクエスト料金がかかる
- コンピューティング料金とリクエスト料金とも無料枠がある
- AWS Lambda 料金
・リクエスト リクエスト 100 万件あたり 0.20USD
・実行時間 GB-秒あたり 0.0000166667USD
- 無料利用枠
・1 か月ごとに 100 万件の無料リクエスト
・40 万 GB-秒のコンピューティング時間
例 関数に 512 MB のメモリを割り当て、3,000,000 回実行し、 毎回の実行時間が 1 秒間だった場合、料金は以下のようになります。
|
(A)1 か月のコンピューティング料金 1.実行時間を秒に換算 合計コンピューティング (秒) = 3,000,000回 × 1 秒/1回の処理時間 = 3,000,000 秒 2.メモリ使用量をGBに換算 合計コンピューティング (GB-秒) = 3,000,000秒 × 512 MB ÷ 1024 = 1,500,000 GB-秒 3.無料枠を減算した使用量 1,500,000 GB-秒 – 400,000 GB-秒の無料利用枠 = 1,100,000 GB-秒 4.1 か月のコンピューティング料金 1 か月のコンピューティング料金 = 1,100,000 × 0.00001667 USD = 18.34 USD |
|
(B)1 か月のリクエスト料金 1.無料枠を減算した請求リクエスト数 3,000,000 件のリクエスト – 1,000,000 件の利用無料枠のリクエスト = 2,000,000 件の請求リクエスト 2.100 万件あたりの1 か月のリクエスト料金 1 か月のリクエスト料金 = 2,000,000 × 0.2 USD ÷ 1,000,000 = 0.40 USD |
|
(C)合計月額料金 合計料金 = コンピューティング料金 + リクエスト料金 = 18.34 USD + 0.40 USD = 18.74 USD/月 |
重要ポイント
・実行されている時間に対してミリ秒単位の無駄のない課金がなされる
・実行されていない待機時間には課金されない
◆ 他のAWSサービスとの連携
Lambdaは、たとえば下記のようなイベントをトリガーとして実行される
- 特定の時間になったとき(CloudWatch Events)
- S3にデータがアップロードされたとき
- DynamoDBに新しいアイテムが書き込まれたとき
- Auto Scalingアクションが実行されたとき
- Webページでボタンが押されたとき
- Kinesisにレコードが追加されたとき(Kinesisではリアルタイムなデータストリーミングを処理する)
- 「Alexa、〇〇について教えて」と言ったとき
AWS Lambdaを使用すことで、サーバーレスアーキテクチャ(サーバーの準備・管理を必要としない設計)を構築することができる。
ソースコードはAWS CodeCommitなどのリポジトリでバージョン管理できる
重要ポイント
・AWSサービスの処理を簡単に自動化できる
・AWSサービスからのトリガーを使用することで、イベントからLambdaを実行できる
5-5 その他のコンピューティングサービス
| ECS | 「Amazon Elastic Container Service」の略。コンテナ管理を行うマネージドサービス |
| Lightsail | Amazon Lightsailは、AWSが提供する仮想プライベートサーバー |
| Batch | AWS Batchは、フルマネージド型のバッチ処理実行環境サーバー |
❏第6章 ストレージサービス
6-1 EBS
|
EBSは、Amazon Elastic Block Storeの略。EC2インスタンスにアタッチして使用するブロックストレージボリューム。次の特徴がある
|
165頁 |
|
EC2インスタンスのボリュームとして使用 |
165頁 |
EBSはEC2インスタンスのルートボリューム(ブートボリューム)、または追加のボリュームとして使用する。EC2インスタンスと同様、
不要になればいつでも削除することができる
重要ポイント
・必要なときに必要な量を利用できる
|
アベイラビリティゾーン内でレプリケート |
166頁 |
EBSは同じアベイラビリティゾーン内の複数サーバー間で自動的にレプリケートされるためハードウェア障害が発生してもデータが失われることを防ぐ
重要ポイント
・アベイラビリティゾーンの変更が可能
|
ボリュームタイプの変更が可能 |
166頁 |
- 汎用SSD
性能は、最大でも16,000 IOPS(1秒あたりにディスクが処理できるI/Oアクセスの数)で、かつ一定の性能を約束するものではない - プロビジョンドIOPS SSD
持続的で一定のIOPSが必要な場合や、16,000 を超えるIOPSが必要な場合(最大値 64,000) - スループット最適化HDD、Cold HDD
SSDほどの性能を必要とせず、コストを節約したい場合はスループット最適HDD、さらにアクセス頻度が低い場合はCold HDDを検討。
両方ともルートボリューム(ブートボリューム)として使用できない。追加のボリュームとして使用できる
重要ポイント
・使い始めた後にオンラインでボリュームタイプを変更できる
|
容量の変更が可能 EBSは、確保しているストレージ容量に対して課金が発生する。ストレージ容量は使用を開始した後にもオンライで増やすことができる |
167頁 |
重要ポイント
・使い始めた後にオンラインでストレージ容量を増やすことができる
|
高い耐久性のスナップショット
EBSは同じアベイラビリティゾーン内の複数サーバー間で自動的にレプリケートされるが、そのアベイラビリティゾーンが使えなくなったとき、EBSも使えなくなる。EBSのスナップショットを作成すると、S3の機能を使ってスナップショットが保存される。 |
167頁 |
重要ポイント
・スナップショットはS3の機能を使って保存される(高い耐久性)
|
ボリュームの暗号化 EBSの暗号化を有効にすればボリュームが暗号化される。ボリュームを暗号化すると、そのボリュームから作成されたスナップショットも暗号化される。EC2インスタンスからデータの暗号化/復号化は透過的に行われるので、プログラムやユーザーから追加の操作を行う必要はない |
168頁 |
重要ポイント
・EBSの暗号化に対して追加の操作は必要ない
|
永続的ストレージ EBSはインスタンスのホストとは異なるハードウェアで管理されているので、インスタンスを一旦停止して再開したときも、EBSに保存されたデータは残っている。 |
169頁 |
◆ インスタンスストア
EBSに対して、インスタンスのホストローカルのストレージを使用するのはインスタンスストア。EC2インスタンスを停止すると、インスタンスストアのデータは失われる
重要ポイント
・EBSのデータは永続的、インスタンスストアは一時的
6-2 S3
|
Amazon Simple Storage Serviceの略。Sが3つ並ぶのでS3.インターネット対応の完全マネージド型のオブジェクトストレージ |
170頁 |
|
S3の特徴 |
- 無制限のストレージ容量
- 高い耐久性
- インターネット経由でアクセス
◆ 無制限のストレージ容量
- バケットというデータの入れものを作れば、データを保存し始めることができる
- 保存できるデータ容量は無制限
- 1つのファイルについて5TBまでとい制限がある
重要ポイント
・S3のオブジェクト容量は無制限
・ストレージ容量の確保/調達をきにすることなく開発に専念できる
◆ 高い耐久性
S3ではリージョンを選択してバケットを作成し、データをオブジェクトとしてアップロードする。そのオブジェクトは1つのリージョン内の複数のアベイラビリティゾーンにまたがって、自動的に冗長化して保存される
重要ポイント
・S3の耐久性はイレブンナイン(99.999999999%) ・冗長化やバックアップを意識することなく開発に専念できる
◆ インターネット経由でアクセス
S3にはインターネット経由(HTTP/HTTPS)でアクセスする。AWSの他のサービスがそうであるように、S3も、マネージメントコンソールからも、
AWS CLI (コマンドラインインターフェース)、SDK(ソフトウェアデベロップメントキット)、API からもアクセスできる
重要ポイント
・S3は世界中のどこからでもアクセスできる
|
S3のセキュリティ |
172頁 |
◆ アクセス権限
S3側で設定するアクセス権限には以下の3種類がある
- アクセスコントロールリスト(ACL)
- バケットポリシー
- IAMポリシー
バケットには、アクセスコントロールリストとバケットポリシーが設定できる
オブジェクトには、アクセスコントロールリストが設定できる
バケットポリシーで個別にオブジェクトを指定することもできる
| アクセスコントロールリスト(ACL) |
・他の特定のAWSアカウントにオブジェクトの [ 一覧を許可|書き込みを許可|読み込みを許可 ]できる ・誰にでもオブジェクトの [ 一覧を許可|書き込みを許可|読み込みを許可 ]できる ・アクセスコントロールリストはバケットに対しても個別のオブジェクに対しても設定できる
・次のコードは、AWS CLI コマンドでアップロードして読み取り許可を設定する例 |
| バケットポリシー |
・アクセスコントロールリストのバケット単位、オブジェクト単位より、より細かい設定が可能 ・特定のIPアドレスからの、tmp/以下のオブジェクトに読み取りアクセスのみ許可や ・誰からでもバケット全体へアクセスできるように設定することも可能 |
| IAMポリシー |
・IAMユーザーに対してアクセス権を設定できる ・AWSサービスにS3へのアクセス権を設定する際にもIAMポリシーが使える ・IAMポリシーをアタッチしたIAMロールを作成し、そのロールをEC2インスタンスに設定することで、そこで動作するプログラムに対してS3へのアクセス許可を与えられる |
◆ 通信、保存データの暗号化
| 通信中のデータの暗号化 |
S3にはhttp/httpsでアクセスすることが可能。仮想ホスト形式ではリージョンを省略することができる ・パス形式 http://s3-ap-northeast-1.amazonaws.com/bucket / https://s3-ap-northeast-1.amazonaws.com/bucket |
| 保存データの暗号化 |
S3に保存するデータの暗号化方法には、次の3種類がある ・KMS(AWS上で暗号化のためのキーを作成・管理し、暗号化を制御)を使用したサーバーサイド、またはクライアントサイド暗号化 ・お客様独自のキーを使用したサーバーサイド、またはクライアントサイド暗号化 |
重要ポイント
・S3バケット、オブジェクトはデフォルトでプライベート ・アクセスコントロールリストで簡単にアクセス権を設定できる ・バケットポリシーでより詳細にアクセス権を設定できる ・EC2などのAWSリソースにS3へのアクセス権を設定する際はIAMポリシーを使用する ・HTTPSでアクセスできる ・保存データの暗号化は複数の方法から選択できる
|
S3の料金 S3の料金は主に次の3要素 |
180頁 |
- 保存しているオブジェクトの容量に対しての料金を、1か月全体を通しての平均保存量で算出
- リージョンによって料金が異なる
- ストレージクラスによっても料金が異なる。次のストレージクラスがある
| 標準 | 対象オブジェクト |
ストレージクラスを指定しない場合のデフォルトのストレージクラス |
| 料金(執筆時点) | 東京リージョンの料金は0.025USD/GB(最初の50TB) | |
| ユースケース | アプリケーションによって頻繁に利用されるオブジェクトや静的Webコンテンツの配信 | |
| 低頻度アクセス(標準IA) | 対象オブジェクト |
アクセス頻度の少ないオブジェクトを格納することで、S3のトータルコストを下げることができる |
| 料金(執筆時点) |
東京リージョンの料金は0.019USD/GB。ストレージ料金は標準ストレージよりも安価だが、リクエスト料金が標準ストレージよりも上がる |
|
| ユースケース | バックアップデータ | |
| 1ゾーン低頻度アクセス(1ゾーンIA) | 対象オブジェクト |
アクセスする頻度が少なく、複数のアベイラビリティゾーンに冗長化される可用性を必要としないオブジェクトを保存する場合に使用 |
| 料金(執筆時点) | 東京リージョンの料金は0.0152USD/GB | |
| ユースケース | 複数リージョンにバックアップデータを保存する場合など、該当のS3以外にもデータの複製があるケース | |
| Amazon Glacier | 対象オブジェクト | リアルタイムなアクセスは必要ないが、保存はしておかなければならないような、アーカイブデータを格納 |
| 料金(執筆時点) | 東京リージョンの料金は0.005USD/GB | |
| ユースケース |
アクセスすることはほとんどなくても削除はできないデータ オブジェクトにアクセスするときは数時間かかる取り出し作業が必要 |

● ライフサイクルポリシー
アップロードした日から起算して自動でストレージクラスを変更することが可能
以下はその例(図)
|
1.EC2(EBS)には当日のエラーログのみ配置。 |
|
2.過去のエラーログはS3へ保存。S3へのアップロードから30日間は、調査などのために参照する可能性があるので、標準ストレージを使用 |
|
3.以降30日間はあまりアクセスすることはないが、緊急で調査が必要になる場合があるので低頻度アクセスストレージを使用 |
|
4.60日が経過するとほどんど参照しないが、会社規定で1年間の保存が義務づけられているのでGlacierにアーカイブする |
|
5.1年経過すると自動で削除する |
2.リクエスト料金
データをアップロードしたりダウンロードするリクエストに対しての料金
3.データ転送料金
- リージョンの外にデータを転送した場合にのみ発生する
- リージョンによって異なる
- インターネットへ転送した場合と他のリージョンへ転送した場合でも料金が異なる
- インターネットからAmazon S3へのデータ転送受信(イン)には課金がかからない
- リージョン外であっても、CloudFrontへの転送料金は課金対象外
重要ポイント
・ストレージ料金はストレージクラスによりコスト効率を高めることができる ・ライフサイクルポリシーによりストレージクラスの変更を自動化できる ・リージョンの外へのアウト通信のみデータ転送料金が発生する
|
S3のユースケー
|
184頁 |
6-3 その他のストレージサービス
| EFS | 複数のEC2インスタンスでマウントして共有利用できるファイルストレージサービス |
| Storage Geteway | オンプレミスアプリケーションとAWSストレージサービスを、シームレスに接続して利用することができるゲートウェイサービス |
| Snowball | 物理デバイスを使用して、ペタバイト級の大容量データ転送を行うことができるサービス |
補足
Amazon EBS と Amazon S3 の違い| EBS | S3 |
|---|---|
| EC2にアタッチできる | EC2にアタッチできない |
| データを出し入れする速度が速い | データを出し入れする速度がEBSより遅い |
| 容量を確定してからアタッチする(上限16TB) | 容量制限が無い |
| 使用容量ではなくアタッチ時に確定した容量分に課金される |
使用容量分に課金される |
| 月額 0.12USD/1GB(汎用ストレージ) | 月額 0.025USD/1GB EBSより5分の1程度も安い |
引用 同じストレージなのに何が違うの?EBSとS3の違い
❏第7章 ネットワークサービス
7-1 VPC
|
VPCの概要 VPCはAmazon Virtual Private Cloudの略。AWSクラウド内にプライベートなネットワーク環境を構築することができる。お客様は標準的なネットワーク構成項目を設定でき、ネットワーク構成やトラフィックを完全にコントロールすることができる。AWSのサービスの中にはVPC内で利用するものとVPC外で利用するものがある。以下は主な機能要素
|
193頁 |
重要ポイント
・VPCは、隔離されたプライベートなネットワーク構成をお客様がコントロールできるサービス
|
VPCの作成 VPCは、リージョンを選択して複数のアベイラビリティゾーンをまたがって作成する。VPCを作成するときIPアドレスの範囲をCIDRで定義する |
194頁 |
◆ CIDR
CIDRでは、10.0.0.0/16のようにIPアドレスの範囲を定義する
重要ポイント
・VPCはリージョンを選択して作成
・CIDRでVPCのプライベートIPアドレスの範囲を定義
|
サブネット VPCで設定したアドレス範囲をサブネットに分けて定義する。サブネットを作成するときにアベイラビリティゾーンとIPアドレス範囲を定義する。同一VPC内の他のサブネットと重複はできない。サブネットの最初の4つと最後の1つはAWSで予約されていて使えない
|
195頁 |
重要ポイント
・サブネットはアベイラビリティゾーンを選択して作成
・CIDRでサブネットのプライベートIPアドレスの範囲を定義
|
インターネットゲートウェイ VPCとパブリックインターネットを接続するためのゲートウェイ。VPCにつき1つのみ作成できる。インターネットゲートウェイ自体が水平スケーリングによる冗長性と高い可用性を持っているため単一障害点にはならない |
196頁 |
重要ポイント
・インターネットゲートウェイはVPCとパブリックインターネットを接続
・インターネットゲートウェイ自体は高可用性と冗長性を持っている
|
ルートテーブル サブネットの経路をルートテーブルで設定する。ルートテーブルはVPCを選択して作成する。続いてエントリを設定してサブネットに関連づける |
196頁 |
重要ポイント
・ルートテーブルはサブネットに関連付ける
・サブネット内のリソースがどこに接続できるかを定義する
|
パブリックサブネットとプライベートサブネット 特別な要件がない最小構成は各アベイラビリティゾーンに2つの役割でサブネットを分割。その2つの役割は、インターネットに対して直接ルートを持つパブリックサブネットと、ルートを持たないプライベートサブネット
● パブリックサブネット ・パブリックサブネット内のインスタンスなどのリソースは、外部との直接通信ができる
● プライベートサブネット ・インターネットゲートウェイに対してのルートを持たないルートテーブルに関連付けられている ・プライベートサブネット内のインスタンスは外部アクセスから保護できる ・各サブネットの間にローカル接続のルートがあるので、プライベートサブネット内のリソースはサブネット内のリソースと通知できる |
197頁 |
重要ポイント
・サブネットは役割で分割する
・外部インターネットに接続できるのがパブリックサブネット
・外部インターネットに接続せず外部アクセスからリソース保護できるのがプライベートサブネット
|
セキュリティグループ 1つのセキュリティグループを複数のインスタンスに設定することができる。セキュリティグループの送信元はCIDRでIPアドレス範囲を指定するか、他のセキュリティグループのIDを指定することができる。セキュリティグループはVPCを指定して作成する。デフォルトではインバウンド(受信)へのアクセスがすべて拒否されているので、許可(ホワイトリスト)するものだけを設定する |
198頁 |
重要ポイント
・セキュリティグループは、インスタンスに対してトラフィックを制御する仮想ファイアウォール
・許可するインバウンドのポートと送信元を設定するホワイトリスト
・送信元には、CIDDRか他のセキュリティグループIDを指定できる
|
ネットワークACL ネットワークACL(アクセスコントロールリスト)はサブネットに対して設定する仮想ファイアウォール機能。サブネット内のすべてのリソースに対してのトラフィックに影響がある。デフォルトですべてのインバウンドとアウトバウンドが許可されているので、拒否(ブラックリスト)の設定を行う |
200頁 |
重要ポイント
・ネットワークACLは、サブネットに対してのトラフィックを制御する仮想ファイアウォール
・拒否するインバウンドのポートと送信元を設定するブラックリスト
・必要がなければ設定しない追加のセキュリティレイヤー
|
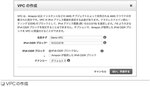
構成例:基本構成でWebサーバーを起動 ここではVPCを作ってパブリックサブネット内でEC2サーバーを起動して、インターネット経由でブラウザからアクセスしてみる。 最小の推奨構成例として、2つのアベイラビリティゾーン上にパブリックサブネットを1つづつ、プライベートサブネットを1つ づつ作成する(図1) |
201頁 |
- まずVPCダッシュボードで東京リージョンを選択する(図2)
- VPCを作成。CIDRは10.0.0.0/16とする(図3)
・名前タグ「Demo VPC」
・VPC作成以降のIGW、サブネット、ルートテーブル、セキュリティグループの作成は左メニューから遷移する - インターネットゲートウェイを作成して、VPCにアタッチする(図4)
・名前タグ「Demo IGW」
・IGWをVPCにアタッチする手順:IGW一覧でName「Demo IGW」を選択 > アクション > VPCにアタッチ - パブリックサブネットとプライベートサブネットを作成(図5)
・サブネット の作成では「新しいサブネットを追加」ボタンで計4件入力する------------------------------------------------------------------------------------------------
Public Subnet1 ap-northeast-1a 10.0.1.0/24
Public Subnet2 ap-northeast-1c 10.0.2.0/24
Private Subnet1 ap-northeast-1a 10.0.3.0/24
Private Subnet2 ap-northeast-1c 10.0.4.0/24
------------------------------------------------------------------------------------------------
- パブリックサブネット用のルートテーブルを作成(図6)
・名前タグ「Demo Public Route Table」
- インターネットゲートウェイのID(igwで始まるID)へのエントリを設定し、サブネットに関連付る(図7)
・ルートテーブル一覧でName「Demo Public Route Table」を選択して、IGW やサブネットへの関連付けを行う
・IGWへのエントリ手順:ルートタブ > ルートの編集 > ルートの追加
送信先:0.0.0.0/0、ターゲット:プルダウンからInternet Gatewayをクリックして名前タグ「Demo IGW」を選択
・サブネットに関連付ける手順:サブネットの関連付けタブ > サブネットの関連付けの編集
サブネット一覧から「Public Subnet1」「Public Subnet2」をチェックして保存 - セキュリティグループを作成(図8)
・セキュリティグループ名「Web Security Group」、説明「For Web Server」、VPC「Demo VPC」を選択
- 80番ポートを任意の場所からアクセスできるようにし、22番ポートには「マイIP」を選択して、今インターネットに接続している
グローバルIPアドレスを指定する(図9)
・インバウンドルール
----------------------------------------
(タイプ) (ソース)
HTTP 0.0.0.0/0
SSH マイIP
----------------------------------------
- これでVPCの設定は完了
- 続いてEC2を起動する
- EC2のダッシュボードから以下の手順を実施 ※詳細は前述の「EC2インスタンスの起動 109頁」を参照
- 東京リージョンを選択して[インスタンスの作成]ボタンを押下
- AMIにはAmazon Linuxをを選択
- インスタンスタイプにはt2.microを選択
- ステップ3 インスタンスの詳細の設定ではネットワーク設定を行う
- VPCを選択
・VPCに「Demo VPC」を選択 - サブネットにPublic Subnet 1 を選択
・サブネットに「Public Subnet1」を選択 - 外部から直接アクセスするのでパブリックIPアドレスで有効化を選択
・自動割り当てパブリック IPを「有効」にする
- VPCを選択
- ユーザーデータに次のコードをテキストで入力する
#!/bin/bash
yum -y install httpd
systemctl start httpd.service
systemctl enable httpd.service - ストレージはデフォルトのまま
- タグの設定では「Name」キーの値を「Web Server」にする
- セキュリティグループには、あらかじめ作成しておいた「Web Security Group」を選択
- 確認画面で[作成]ボタンを押下
- キーペアは既存のものを使用するか、新規作成する
- EC2が起動されたら、割り当てられているパブリックIPアドレスをコピーしてブラウザに貼り付けてアクセスしてみる
Apacheのデモ画面が表示され、外部からアクセスできたことが確認できる








重要ポイント
・インターネットゲートウェイをVPCにアタッチする ・インターネットゲートウェイへの経路を持つルートテーブルをサブネットに関連付る ・EC2インスタンスをそのサブネット内で起動する ・EC2インスタンスにパブリックIPアドレスを有効にするか、EC2のパブリックIPアドレスを固定するElasticIPをアタッチする
|
ハイブリッド環境構成 既存のオンプレミス環境の拡張先としてAWSを使うことができる。オンプレミスとクラウドの両方を活用する構成をハイブリッド環境構成という |
209頁 |
◆ ハードウェアVPN接続
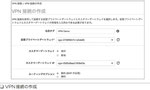
AWSに作成した仮想プライベートゲートウェイと、オンプレミス側のカスタマーゲートウェイを指定してVPN接続を作成できる。たとえば社内のプライベートネットーワークのみで稼働する業務アプリケーションをAWSで実現できる(図1)
- 仮想プライベートゲートウェイを作成し、VPCにアタッチする(図2)
- オンプレミス側のカスタマーゲートウェイの設定を行う(図3)
- 仮想プライベートゲートウェイとカスタマーゲートウェイを指定してVPN接続の設定を行う(図4)
- カスタマーゲートウェイ側のメーカーに応じて設定をダウンロードすることができる(図5)




◆ ダイレクトコネクト
帯域を確保するため、もしくはセキュリティとコンプライアンス要件を満たすために専用線を選択することができる。
ダイレクトコネクト(AWS Direct Connect)を使用することで、AWSとデータセンターの間でプライベートなネットワーク接続を確立できる
◆ VPCピアリング接続
オンプレミスとの接続以外にも、複数のVPC同士を接続する、VPCピアリング接続という機能もある。VPCピアリング接続を使うと、同じリージョン、同じアカウントだけでなく、別のリージョン、別のアカウントの複数のVPCとも接続できる。他にVPCに接続する方法として、大規模ネットワークの構築も可能なAWS Transit Geteway や、クライアントベースのAWS Client VPN がある
重要ポイント
・VPCと既存のオンプレミス環境をVPN接続できる
・VPCと既存のオンプレミス環境をダイレクトコネクトを使って専用線で接続できる
7-2 CloudFront
|
Amazon CloudFrontはエッジロケーションを使い、最も低いレイテンシー(遅延度)のコンテンツ配信ネットワークサービス
|
213頁 |
重要ポイント
・CloudFrontはエッジロケーションを使用するCDNサービス
|
CloudFrontの特徴
|
213頁 |
◆ キャッシュによる低レイテンシー配信
同じ場所にいる3人のユーザーがアクセスしたとき、1人目のユーザーはオリジナルコンテンツから配信をCloudFront経由で受けることになるが、2人目、3人目はオリジナルコンテンツにはアクセスせず、CloudFrontのキャッシュから配信を受けることができ、遅延なくブラウザに表示できる
重要ポイント
・エッジロケーションにキャッシュを持つことで低レイテンシー配信を実現
◆ ユーザーの近くから低レイテンシー配信
エッジロケーションにキャッシュがないタイイングでも、エッジロケーションと各リージョンの間はAWSのバックボーンネットワークを経由しているので、直接アクセスするよりもより良いネットワークパフォーマンスが提供される
重要ポイント
・世界中のエッジロケーションが利用できるので、ユーザーへは最もレイテンシーの低いエッジロケーションから配信される
◆ 安全性の高いセキュリティ
CloudFrontにはお客様が所有しているドメインの証明書を設定できる。これにより、ユーザーからHTTPSのアクセスを受けることができ、通信データを保護できる。証明書はAWS Certificate Manager を使用すると、追加費用なしで作成、管理できる。AWS Shield、AWS WAF といったセキュリティサービスと組み合わせることで、外部からの攻撃や脅威からオリジナルコンテンツを保護できる。AWS Shield Standard は追加費用なしで利用できる
重要ポイント
・通信の保護するために証明書を設定できる
・外部の攻撃からも守ることができる
7-3 Route 53
|
Amazon Route 53はエッジロケーションで利用されるDNSサービス。一般的なDNSサービス同様に、ドメインに対してのIPアドレスをマッピングしてユーザーからの問い合わせに回答する |
217頁 |
重要ポイント
・Route 53 はエッジロケーションで使用されるDNSサービス
|
Route 53 の主な特徴
|
217頁 |
◆ 様々なルーティング機能
|
・シンプルルーティング 問い合わせに対して、単一のIPアドレス情報を回答 |
|
・レイテンシーベースのルーティング/Geo DNS 1つのドメインに対して複数のDNSレコードを用意しておき、地理的な場所を近くしてレイテンシー(遅延度)が低くなるようにルーティングを行う |
|
・加重ラウンドロビン 1つのドメインに対して複数のDNSレコードを用意しておき、割合を決める。その割合に応じて回答する |
|
・複数地回答 複数のレコードからランダムに回答する |
重要ポイント
・複数のレコードを設定し、用途に応じて最適なルーティングを選択できる
◆ 高可用性を実現するヘルスチェックとフェイルオーバー
ヘルスチェックを組み合わせることで、システム全体の可用性を高められる。ルーティングの種類の1つにフェイルオーバーがあり、プライマリとセカンダリーを設定しておき、プライマリのヘルスチェックが失敗したときセカンダリーのレコードを回答する
重要ポイント
・複数のレコードを設定し、システムの高可用性を世界中のリージョンを使用して実現できる
◆ ルートドメイン(Zone Apex)のエイリアスレコード
Route 53 ではAレコードなどの各レコードセットにエイリアス(別名)を設定することができる。エイリアスはZone Apex と呼ばれる、サブドメインのないトップレベルのルートドメインにも設定できる。これにより、ルートドメインにも複数のリソースを設定でき、可用性の高いシステム構成を作ることができる
重要ポイント
・Zone Apex に対して柔軟な設定ができ、高可用性を実現できる
❏第8章 データベースサービス
8-1 RDS
|
RDSの概要 RDSはAmazon Relational Database Service の略。使用できるデータベースエンジンは次の6つ
|
227頁 |
重要ポイント
・オンプレミスで使われているデータベースをそのまま簡単に使うことができる
|
RDSとEC2の違い EC2で起動したサーバーにデータベースエンジンをインストールするより、RDSでデータベースエンジンを使用することで、次の3つの管理タスクから解放され開発に注力できるようになる
|
228頁 |
重要ポイント
・RDSを使うことでインフラ管理から解放され、本来やるべき開発に注力できる
◆ メンテナンス
RDSを使用すると、お客さまはOSを意識する必要がなくなる。OSのメンテナンスは週1回、お客様が設定した時間に自動的に行われる。データベースのマイナーバージョンアップグレードを自動適用するかどうかもお客様が選択できる
重要ポイント
・OS,データベースエンジンのメンテナンスをAWSに任せることができる
◆ バックアップ
RDSでは、デフォルトで7日間の自動バックアップが適用される。バックアップの期間は0~35日間まで設定でき、指定した時間にバックアップデータが作成される
● ポイントタイムリカバリー
自動バックアップを設定している期間内であれば、秒数までを指定して特定の時点のインスタンスを復元できる
重要ポイント
・データベースのバックアップを管理しなくても良い
・バックアップ期間中の任意の特定時間のインスタンスを起動できる
◆ 高可用性
RDSのマルチAZ配置をオンにすると、アベイラビリティゾーンをまたいだレプリケーションが自動的に行われる。マスターに障害が発生した際のフェイルオーバーも自動的に行なわれる。
重要ポイント
・マルチAZ配置を使用するとでデータベースの高可用性を実現できる
・レプリケーション、フェイルオーバーはRDSの機能によって自動的に行われる
|
Amazon Auroraの概要 MySQL、PostgreSQLのインターフェース機能を持っており、MySQL、PostgreSQLを使用しているアプリケーションはAuroraをそのまま使用できる可能性が高い。Auroraの利用する主なメリットは次のとおり
|
233頁 |
重要ポイント
・Amazon AuroraはMySQL/PostgreSQL互換の、クラウドに最適化されたリレーショナルデータベース
|
DMS AWS Database Migration Service の略。オンプレミスの従来のデータベースからRDSにデータを継続的に移行できる。移行時のシステムダウンタイムも最小限に抑えられ、異なったデータベースエンジンでも移行が可能 |
234頁 |
重要ポイント
・DMSはデータベース間でデータを移行できるサービス
・DMSによりオンプレミスからAWSへの継続的なデータ移行を行い、システムのダウンタイムを最小限にできる
8-2 DynamoDB
|
Amazon DynamoDB はNoSQL型の高いパフォーマンスを持ったフルマネージド型のデータベースサービス。フルマネージド型とは
|
235頁 |
重要ポイント
・DynamoDBはフルマネージドなデータベースサービス
・リージョンを選択して使うことができる
|
DynamoDBとRDSの違い
|
236頁 |
| RDS |
・RDSはリレーショナルデータベース ・トランザクションをコミットにより確定できるので、厳密な確定処理をすることにむいている ・大量のデータ更新や読み込みを必要とする処理に向いてない ・垂直スケーリングができる(1つのインスタンスで処理を行う) ・データはSQL型のテーブル形式(図1) |
| DynamoDB |
・DynamoDBは非リレーショナルデータベースやNoSQLと言われている ・厳密なトランザクションを必要とする処理や、複雑なクエリには向かない ・大量のアクセスがあってもパフォーマンスを保ったまま処理ができる ・水平スケーリングができる ・NoSQL型のテーブル形式。1つのデータはアイテム(項目)として扱う。キーとして設定している属性と値さえあれば、 それ以外の属性は動的で自由(図2) |


重要ポイント
・データの特徴やシステムの要件に応じて適したデータベースサービスを選択する
・中規模程度のアクセス量で、整合性や複雑なクエリを必要とする場合はRDSを選択する
・大規模なアクセス量で、単純な自由度の高いデータモデルを扱う場合はDynamoDBを選択する
8-3 その他のデータベースエンジン
|
・Amazon Redshift 高速でシンプルなデータウェアハウスサービス。データ分析に使用。大規模なデータ分析にも対応 |
|
・Amazon ElastiCache インメモリデータストアサービス。RDSやDynamoDBのクエリ結果のキャッシュや、アプリケーションのセッション情報を管理する用途に使用 |
|
・Amazon Neptune フルマネージドなグラフデータベースサービス。SNS、レコメンデーション(提案)エンジン、経路案内、物流最適化などのアプリケーション機能に使用 |
❏第9章 管理サービス
9-1 CloudWatch
|
各インスタンスの現在の状態、情報をモニタリングするサービス。CloudWatchは標準メトリクスという、AWSが管理している範囲の情報を、お客様側での追加の設定なしで収集している。メトリクスデータはダッシュボードで可視化でき、アラーム設定することもできる
|
245頁 |
重要ポイント
・AWSのサービスを使い始めると、サービスにより起動されたリソースのメトリクスがCloudWatchに自動的に収集し始める
|
CloudWatchの特徴
|
246頁 |
◆ 標準(組み込み)メトリクスの収集、可視化
AWSがコントロールできる範囲の、AWSが提供している範囲で知り得る情報を標準メトリクスとして収集している。EC2では、CPU使用率や、ハードウェアやネットワークのステータス情報が標準メトリクスとして収集されている。標準メトリクスとして収集された値は、マネジメントコンソールのメトリクス画面やダッシュボードで可視化できる
重要ポイント
・標準メトリクスは、使用するサービスによって取得される情報が異なる
◆ カスタムメトリクスの収集、可視化
CloudWatchのPutMetricData API を使用してCloudWatchへカスタムメトリクスとして書き込むことができる。CloudWatchへメトリクスを書き込むプログラムはCloudWatchエージェントとして提供されているので、EC2へインストールするだけで使用できる。カスタムメトリクスとして収集された値もマネジメントコンソールのメトリクス画面やダッシュボードで可視化できる
重要ポイント
・EC2のカスタムメトリクスはCloudWatchエージェントで取得できる
◆ ログの収集
- CloudWatch Logs では、EC2のアプリケーションのログや、Lambdaのログ、VPC Flow Logs などを収集することができる
- EC2では、カスタムメトリクス同様にCloudWatchエージェントをインストールして少しの設定をすることでCloudWarch Logs へ書き出せる
- 障害が発生してログ調査が必要になった場合、CloudWatch Logs に書き出しておけば、異常なインスタンスや不要になったインスタンスをその時点でAuto Scaling によって終了させることができ、後でログを分析して調査できる
- CloudWatch Logs は出現文字でフィルタリングしてメトリクスとして扱うこともできる
重要ポイント
・EC2のCloudWatch Logs はCloudWatchエージェントで取得できる
・CloudWatch Logs によりEC2をよりステートレスにできる
・CloudWatch Logs は文字列のフィルタリング結果をメトリクスとして扱える
◆ アラーム
CloudWatchでは、各サービスから収集したメトリクス値に対してアラームを設定することができる
アラームに対して次の3つのアクションを実行できる
|
・EC2の回復 EC2のホストに障害が発生したときに自動で回復させる |
|
・Auto Scalingの実行 Auto Scalingポリシーでは、CloudWatchアラートに基づいて、スケールイン/スケールアウトのアクションを実行する |
|
・SNSへの通知 Amazon Simple Notification Service によりSNSへ通知することができる |
重要ポイント
・アラームを設定することにより、モニタリング結果に基づく運用を自動化できる
|
保存期間について
|
252頁 |
| メトリクス |
・60秒未満のデータポイントは3時間 ・1分(詳細モニタリング)のデータポイントは15日間 ・5分(標準)のデータポイントは63日間 ・1時間のデータポイントは455日間 |
| CloudWatch Logs |
・任意の保存期間を設定できる。消去しないことも可能 |
9-2 Trushed Advisor
|
Trushed Advisor は、お客様のAWSアカウント環境の状態を自動的にチェックして回り、ベストプラクティスに対してどうであったかを示すアドバイスをレポートする。チェックする視点は次の5つ
|
253頁 |
重要ポイント
・Trushed Advisor はAWS環境を自動でチェックして、ベストプラクティスに沿ったアドバイスをレポートする
|
コスト最適化 ここを見直せばコストを最適化できる、という視点でチェックしたアドバイスがレポートされる。コスト最適化では、具体的にどれくらい月額コストが下がるかという金額も計算されて提示される |
254頁 |
◆ 使用率の低いEC2インスタンス
使用率が低い状態とは
- 使っていないのに起動中のインスタンスがある
- 検証やテストで使って終了を忘れているインスタンスがある
- 過剰に高いスペックのインスタンスがある
◆ リザーブドインスタンスの最適化
EC2の利用状況をチェックして、リザーブドインスタンスを購入したほうがコスト最適化に繋がるかどうかをレポートする 。このレポートに上がってきた内容で1年または3年の継続が見込めるときは、リザーブドインスタンスを購入することでコストが最適化できる
重要ポイント
・コスト最適化では、無駄なコストが発生してないかがチェックされる
|
パフォーマンス システムのパフォーマンスを低下させる原因となる設定や選択がされていないかチェックする
|
255頁 |
| 使用率の高いEC2インスタンス |
EC2に実装している処理に対してリソースが不足している可能性がある場合、対象の処理が最も早く完了するインスタンスタイプに変更することが推奨される |
| セキュリティグループルールの拡大 |
セキュリティグループのルールが多いとそれだけネットワークトラフィックが制御されることになる。ルールをまとめることができないか、対象のインスタンスにそれだけのポートを必要とする機能を多くインストールしてないか、インスタンスを分けることはできないかを検討する |
| コンテンツ配信の最適化 |
CloudFrontにキャッシュを持つことで、S3から直接配信するよりもパフォーマンスが向上する |
重要ポイント
・パフォーマンスでは、最適なサービス、サイズが選択されているかがチェックされる
|
セキュリティ セキュリティリスクのある環境になっていないかをチェックする
|
255頁 |
| S3パケットのアクセス許可 |
誰でもアクセスできるS3パケットがないかチェックする
|
| セキュリティグループの開かれたグループ |
リスクの高い特定のポートが、送信元無制限でアクセス許可されているセキュリティグループをピックアップする。悪意あるアクセスによって攻撃され、データが漏洩する可能性がある |
| パブリックなスナップショット |
EBSやRDSのスナップショットは必要なアカウント間のみで共有するようにする |
| ルートアカウントのMFA、IAMの使用 |
運用するための最低権限を設定したIAMユーザーを作成して、ルーアカウントにもIAMユーザーにもMFAを設定する |
重要ポイント
・セキュリティでは、環境にリスクのある設定がないかチェックされる
|
フォールトトレランス(耐障害性) 耐障害性がないかチェックする。耐障害性を高めるためのアドバイスを提供
|
256頁 |
| EBSのスナップショット |
EBSのスナップショットが作成されていない、または最後に作成されてから時間が経過したことがチェックされる |
| EC2、ELBの最適化 |
複数のアベイラビリティゾーンでバランス良く配置されているかがチェックされる。ELBではクロスゾーン負荷分散やConnection Draining(セッション完了を待ってから切り離す機能)が無効になっているロードバランサーがないかもチェックされる |
| RDSのマルチAZ |
マルチAZになっていないデータベースインスタンスがチェックされる |
重要ポイント
・フォールトトレランスでは、耐障害性が低い状態がないかがチェックされる
|
サービス制限 AWSアカウントを作った最初の時点では以下の理由でソフトリミット(いくつかのサービス制限された状態)されている。 緩和申請によって制限を超えることができるサービスもある
下図は東京リージョンでは、EC2オンデマンドインスタンスの制限が20になっていて、今現在は1インスタンスしか起動していないので問題ないというレポート(図1)サービス制限を上回りそうな予定がある場合は、事前にAWSへ申請を行う(図2) |
257頁 |

重要ポイント
・意図しない操作や不正アクセスによってお客様に不利益が生じないよう、サービス制限がある
・サービス制限では制限に近づいたサービスがアラート警告される
9-3 その他の管理ツール
|
CloudTrail AWS CloudTrail では、AWSアカウント内のすべてのAPI呼び出しを記録され、監視や調査に使用される。CloudTrail と似たサービスに、 AWS Config がある。AWS Config はAWSリソースの変更を記録する。誰がいつ何を変更したかが自動で記録される |
259頁 |
|
CloudFormation AWS CloudFormation は、AWSの各リソースを含めた環境を自動作成/更新/管理する
|
261頁 |
|
Elastic Beanstalk AWS Elastic Beanstalk では、Webアプリケーションの構築を簡単にAWSに構築する
|
262頁 |
❏第10章 請求と料金
10-1 AWS料金モデル
|
使った分だけの従量課金 必要なときに必要なリソースを使って、使った分にだけ費用が発生する。資本の支出を変動費にすることができる。この消費モデルを組織全体で受け入れることにより、コスト最適化が進む |
269頁 |
重要ポイント
・消費モデルはエンジニアだけではなく組織全体で受け入れる
|
課金体系 サービスによって用途が違うので、課金方式も違う。同じサービスでもリージョンによって料金が異なることもある |
269頁 |
重要ポイント
・課金体系はサービスによって異なる
|
多彩な料金モデル 要件に応じて最適な料金モデルを選択することでコストを最適にできる
|
270頁 |
重要ポイント
・お客様は最適な料金モデルを選択できる
10-2 請求ダッシュボード
|
請求書 どのサービスでどれくらいコストが発生しているかは、請求書で確認できる。請求書は月の途中でも確認できる(図1) 各サービスを展開すると、さらに詳細な情報を確認できる。以下はEC2の東京リージョンの料金$10.44の内訳(図2)
|
271頁 |


重要ポイント
・請求書では月の途中でも課金の状況を確認できる
|
コストエクスプローラーとコスト配分タグ AWSの各サービスの中には、タグ(キーと値の組み合わせ)を付けることができるサービスがあり、このタグをコスト分析のために有効化したのがコスト配分タグ。このコスト配分タグで分けた結果はコストエクスプローラーで可視化したり、CSV形式でダウンロードしたりできる |
272頁 |
重要ポイント
・コスト配分タグによってROI(投資した費用から、どれくらいの利益・効果が得られたのかを表す指標)の請求分析ができる
|
請求アラーム 請求金額もCloudWatchメトリクスの1つ。そのためアラートを設定してアクションを実行することができる 設定予算を超えると予測されたときアラームを発信する、AWS Budgets というサービスもある |
274頁 |
重要ポイント
・請求アラームによって使いすぎ抑止するための通知ができる
Column
|
コストと使用状況レポート コストと使用状況レポートを設定すると、アカウントとそのIAMユーザーが使用した各サービスカテゴリのAWS使用状況が、時間単位または日単位の明細項目として記録できる。また、使用状況のデータを日単位または時間単位で集計することも可能 |
274頁 |
10-3 マルチアカウントの運用
個人や組織で、複数アカウントをそれぞれ管理すると運用が煩雑になるが、便利な管理機能がいくつか用意されている
|
AWS Organizations AWS Organizations を使うと、複数アカウントを一括管理できる |
275頁 |
重要ポイント
・Organizationsで複数アカウントを階層管理できる
|
一括請求(コンソリデーティッドビリング) Organizations の一括請求を使用すことで、複数アカウントの請求を1つの請求にまとめることができる。請求書はアカウントごとに確認できる |
276頁 |
重要ポイント
・Organizations で複数アカウントの一括請求ができる
10-4 AWSのサポートプラン
|
AWSアカウントには4つのサポートプランがある。お客様は適切なサポートプランを選択することで、運用の安全性を保ち、エスカレーションパス(問い合わせ先)を確保できる |
277頁 |
| ベーシックプラン |
・AWSアカウントを作ったときに提供される無料サポートプラン ・技術サポートは、AWSサービスの稼働状況をモニタリングしているヘルスチェックについてのサポートのみ ・Trusted Advisor は最低限必要な項目のみ |
| 開発者プラン |
・29USDか使用料の3%の大きいほう ・技術サポートを作成できるユーザーは1ユーザー(9:00~18:00) ・構成要素についてのアーキテクチャサポート ・Trusted Advisor は最低限必要な項目のみ |
| ビジネスプラン |
・100USDか使用料に応じた計算式の大きいほう ・技術サポートを作成できるユーザーは無制限(24時間) ・アーキテクチャはユースケースのガイダンス ・Trusted Advisor は全項目 ・サポートAPIの使用可 ・サードパーティソフトウェアのサポート |
| エンタープライズプラン |
・15,000USDか使用料に応じた計算式の大きいほう ・技術サポートを作成できるユーザーは無制限(24時間) ・アプリケーションのアーキテクチャサポート ・Trusted Advisor は全項目 ・サポートAPIの使用可 ・サードパーティソフトウェアのサポート ・テクニカルアカウントマネージャー(TAM) ・サポートコンシェルジュ ・ホワイトグローブケースルーティング ・管理ビジネス評価 |
重要ポイント
・エスカレーションパスを用意することは重要
・4つのプランがあり、サポート料金によって段階がある
10-5 その他の請求サポートツール
|
AWS簡易見積もりツール 月の請求金額見込みがどれくらいになるかを事前に計算しておくことができる。AWS料金計算ツールが発表されたため、当サービスは終了予定 |
279頁 |
重要ポイント
・簡易見積もりツールで、請求見込額を事前に計算しておくこができる
|
TCO計算ツール AWSへの移行、導入を検討している際に、オンプレミスで構築した場合とのコスト比較をレポートしてくれるツール |
280頁 |
重要ポイント
・TCO計算ツールはAWSとオンプレミスのコストを比較するツール
❏AWS用語
| 用語 | 説明 | 位置No. |
|---|---|---|
| AMI(アミ) | Amazon Machine Image。インスタンスを起動するのに必要なOSやボリュームの情報、アプリケーションなどを含むインスタンスの起動テンプレート。 インスタンスを立ち上げる際は必ずAMIを指定する | 50 |
| AWS | Amazon Web Services 2006年、Webサービスという形態で、企業を対象にITインフラストラクチャサービスの提供を開始 | 30 |
| Artifact | AWS Artifact。無料でセルフサービス型の、AWSコンプライアンスレポートのダウンロードサービス | 57 |
| Certificate Manager | AWS Certificate Manager | 215 |
| credentials | AWSのAPI操作のために必要なアクセスキーとシークレットキーをクレデンシャル情報と呼ぶ | - |
| Design for Failure | 故障に備えた設計を行い、単一障害点をなくす | 35 |
| CloudFront | Amazon CloudFront。データ、動画、アプリケーションなど、静的・動的なさまざまなWebコンテンツをスムーズに配信できるコンテンツデリバリネットワーク(CDN)の事 | 66 |
| EBS | Amazon Elastic Block Store。ストレージサービスであり、EC2インスタンスは自身にアタッチされたEBSボリュームにアクセスすることがでる | 89 |
| EC2 | Amazon EC2。Amazonが提供している仮想サーバー構築サービス。EC2を利用することで、OSを乗せた仮想環境をクラウド上にすばやく作ることができる | 43 |
| Elastic IP | 固定IPアドレスを利用したい場合はElasticIPを用いる。IPアドレスを指定する事は出来ないが、取得したIPアドレスは専有できる。ElasticIPはEC2インスタンスに紐づけて利用し、紐づけられたインスタンスが固定IPを持つ | 208 |
| ELB | Elastic Load Balancing。AWS上で稼働するロードバランサーサービス | 115 |
| IAM(アイアム) | AWSのユーザーとグループを作成および管理し、アクセス権を使用してAWSリソースへのアクセスを許可あるいは拒否できる | 59 |
| Inspector | Amazon Inspector。AWSのEC2 インスタンスにおいて脆弱性診断を自動で行ってくれるサービス | 56 |
| KMS | AWS Key Management Service。AWS上で暗号化キーを簡単に作成・管理し、幅広いAWSのサービスやアプリケーションでの使用を制御できるサービス | 68 |
| Lambda | サーバーのプロビジョニングや管理の必要なしにコードを実行できるコンピューティングサービス | 150 |
| Organizations | AWS Organizations。複数アカウントを一括管理できる | 275 |
| Outposts | AWS Outposts。オンプレミス施設でAWSサービスを利用 | 81 |
| Route 53 | Amzon Route 53。可用性が高く低レイテンシーなアーキテクチャでDNSサービスを実現するマネージドサービス | 81 |
| S3 | Amazon Simple Storage Serviceの略。インターネット対応の完全マネージド型のオブジェクトストレージ | 170 |
| Sheild | AWS Sheild。AWSにおけるアプリケーションサービスからDDoSに対する保護を提供するサービス | 63 |
| SQS | Amazon SQS。完全マネージド型のメッセージキューイングサービス。キューイングを利用することでシステム間を疎結合にでき、分散アプリケーションの拡張性、可用性を大幅に改善できる | 36 |
| STS | AWS Security Token Service。一時的セキュリティ認証情報を生成、提供するサービス | - |
| Trushed Advisor | AWSインフラストラクチャサービスを監視し、既知のベストプラクティスと比較して、節約やシステムパフォーマンス、セキュリティの観点からチェックをしてくれるプログラム | 235 |
| VPC | Amazon VPC。会員専用の仮想ネットワーク空間 | 43 |
| Well-Architected | AWS Well-Architected。AWSの 概念、設計原則や、ベストプラクティス が説明されたホワイトペーパーの事 | 42 |
| WAF(ワフ) | AWS WAF。Webサイト上のアプリケーションに特化したファイアウォール。一般的なファイアウォールと異なり、データの中身をアプリケーションレベルで解析できるのが特徴 | 66 |
| Wavelength | AWS Wavelength。アプリケーションに10ミリ秒未満のレイテンシーを実現 | 81 |
| Local Zones | AWS Local Zones。エンドユーザーからより近い場所に配置 | 81 |
| アベイラビリティゾーン | 各リージョンに存在するデータセンター | 47 |
| インスタンスストア | EC2インスタンスに内蔵されているローカルストレージ。EC2の一時的なデータが保持され、EC2の停止・終了と共にクリアされる。無料で使用可能 | 169 |
| インメモリデータストアサービス | データをディスクではなくメモリから呼び出すことにより、高速な処理を実現する技術をともなったデータベース管理システム。主にデータウェアハウスシステムによる分析処理に使用 | 238 |
| エッジロケーション | Amazon CloudFrontサービス(コンテンツ配信ネットワーク(CDN))を提供 | 47 |
| キューイングチェーン | システムを疎結合にする一つの方法。システム間をキューでつなぎ、ジョブの受け渡しをメッセージの送受信で行うことで非同期でシステム連携する | 36 |
| 準仮想化(PV) | 準仮想化 (PV) とハードウェア仮想マシン (HVM)) の2種類の仮想化タイプ がある。PV AMI と HVM AMI の主な違いは、起動の方法と、パフォーマンス向上のための特別なハードウェア拡張機能 (CPU、ネットワーク、ストレージ) を利用できるかどうかという点 | 50 |
| セキュリティグループ | 同一グループ外のインスタンスと通信を行う際のトラフィックを制御するファイアウォール。セキュリティグループは、サブネットレベルではなく、インスタンスレベルで設定する | 61 |
| 標準メトリクス | EC2インスタンスのCPU使用率やディスク、ネットワークの利用状況、インスタンスのステータスチェックといった項目が用意されており、閾値を設定するだけですぐに監視をはじめることができる | 245 |
| プロビジョニング | EBSに対して、ボリュームのサイズとして確保した容量のこと | 82 |
| マイクロサービスアーキテクチャ | ソフトウェアアプリケーションを独立して配置可能なサービスの組み合わせ(suite)として設計する方法 | 36 |
| リージョン | 複数のデータセンターが冗長構成される アベイラビリティゾーン を更にまとめた地理的エリアを指し | 47 |
| リードレプリカ | リードレプリカとは更新用データベース(マスター)からレプリケーションされた参照専用のデータベース。 アプリケーション側で更新用データベースと参照用データベース(リードレプリカ)を使い分けることにより負荷分散を実現。 ロードバランサを利用して、参照用アクセスを分散し性能を向上させることができる | 233 |
| ルートボリューム | ストレージシステム(EC2)の管理に役立つ特別なディレクトリと構成ファイルが格納されている場所で、windwowで言う所の「Cドライブ」に該当する | 166 |
引用 AWS用語
❏IT用語
| 用語 | 説明 | 位置No. |
|---|---|---|
| ACL | アクセスコントロールリストとは、通信アクセスを制御するためのリストのこと。一般的には略してACLと呼ばれている。ネットワーク管理者は通信要件に従ってACLを定義してルータを通過するパケットに対して、通過を許可するパケット、通過を拒否するパケットを決められる | 67 |
| CIDR(サイダー) | アドレスクラスの概念を気にしないことで、IPアドレスの割り当てや経路選択などの自由度を上げる仕組み | 194 |
| CDN | ホームページのファイルをいろんなコンピュータに置いて、ホームページを見る人は自分の近くのコンピュータからファイルを受け取ることで、ホームページの表示が速くなったり、たくさんの人が同時に見ても遅くならないようにしてくれるネットワークのこと | 41 |
| DDos攻撃 | ネットワークのトラフィックを増大させ、通信を処理をしているコンピューティングリソース(通信回線やサービスの処理能力)に負荷をかけることによって、サービスを通信困難にしたり、ダウンさせたりする攻撃のこと | 63 |
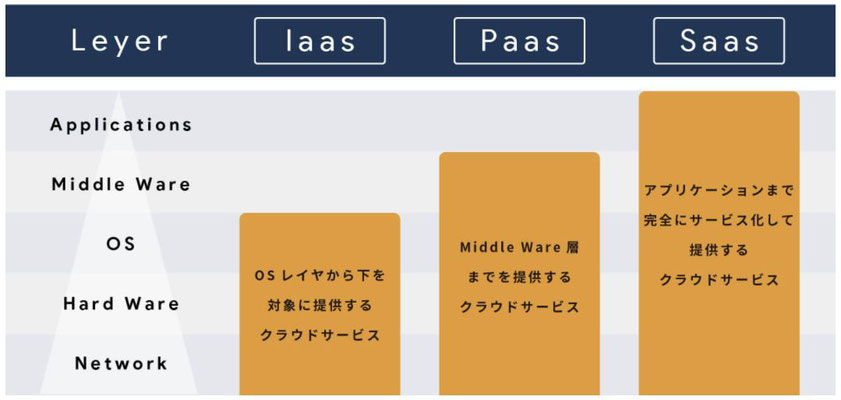
| IaaS(イアース) | 情報システムの稼動に必要な仮想サーバをはじめとした機材やネットワークなどのインフラを、インターネット上のサービスとして提供する形態のこと。ほかSaaS(サース)、PaaS(パース)(図) | 54 |
| ITリソース | コンピューティング(仮想サーバー)、データベース、ストレージ(ディスク領域)、アプリケーションなどのこと | 29 |
| MFA | 「IDとパスワード」に加えて、ユーザ個人が持つ知識・ユーザの生体認証・ユーザの使用端末などより認証セキュリティを厳しく判定するための認証方法 | 51 |
| SNS | Amazon Simple Notification Service。クライアントに対するメッセージの配信および送信を管理するフルマネージド型のウェブサービス | 251 |
| SQLインジェクション | 不正な「SQL」の命令を攻撃対象のウェブサイトに「注入する(インジェクションする)」。例えば、攻撃者がフォームへ不正な内容を盛り込んだSQL文を入力し検索を行うことで、本来は隠されているはずのデータが奪われてしまったり、ウェブサイトが改ざんされてしまったりする | 66 |
| VMエスケープ攻撃 | 攻撃者が仮想マシンから抜け出し、ホスト側のシステムに対してアクセスしたり、任意のコードを実行したりすることが可能となる恐れがある | 50 |
| アーキテクチャ | 基本設計や共通仕様、設計思想などを指す。個別の具体的な製品仕様などではなく、抽象的、基本的な構造や設計を指す | 36 |
| アウトバウンドトラフィック | アウトバウンドは送信。ネットワークを流れるデータのうち、中から外に出ていくデータ(量) | 62 |
| アタッチ・デタッチ | アタッチは接続(追加)する。デタッチは切り離す | 142 |
| アベイラビリティ | システムを正常な状態で継続的に使い続けることができる耐久性のこと | ー |
| インバウンドトラフィック | インバウンドは受信。ネットワークを流れるデータのうち、外から中に入ってくるデータ(量) | 62 |
| インフラストラクチャー | インフラ。ITを使うための基盤となる施設や設備のことを指します | 29 |
| オンデマンド | 「要求に応じて」という意味の英語表現で、利用者の要求に応じてその都度サービスを提供する方式などをこのように呼ぶ。コンピュータの機能やインターネット上のサービスなどのほとんどは、オンデマンド型であると言える。一方、テレビやラジオは決まった時間に決まった内容が流れるため、オンデマンドではない | 29 |
| オンプレミス | サーバー、ネットワーク、ソフトウェアなどの設備を自分たちで導入、運用する | 29 |
| ガバナンス | 企業などが経営方針に則ってIT戦略を策定し、情報システムの導入や運用を組織的に管理・統制する仕組み | 78 |
| クラウド | インターネット経由でITリソースをオンデマンドで利用できる | 29 |
| クロスサイトスクリプト | 掲示板やTwitter等で、攻撃者は、入力内容にスクリプト付のリンクを貼る等の罠を仕掛ける。被害者ユーザが誤って罠を実行する(リンクをクリック)と、セキュリティ的に問題のある別のウェブサイト(クロスサイト)に対し、脆弱性を利用した悪意を持った実行内容(スクリプト)が含まれた通信が実行される | 66 |
| 高可用性 | サービス提供が出来なくなる事態の発生頻度が少ないことを指す(High Availability。HA構成) | 44 |
| コンポーネント |
機械などの構成部分や組み合わせの単位を指す。IT用語としては何らかの機能を持ったプログラム部品のことをいう |
36 |
| シームレス | 複数のシステムや、複数のソフトウェアから構成されているシステムやソフトウェアに対して、複数のシステムや複数のソフトウェアを意識せずに、あたかも、一体のように利用出来る状態のことを「シームレス」、または、「シームレスなシステム」と言う | 185 |
| スケーラブル/スケーラビリティ | 機器やソフトウェア、システムなどの拡張性、拡張可能性のこと | ー |
| スケーリング | 装置やソフトウェア、システムなどの性能や処理能力を、要求される処理量に合わせて増強したり縮減したりすること | 36 |
| スケールアップ | CPUやメモリなどのサーバースペックを増強することでシステムの性能を向上させる | - |
| スケールダウン | CPUやメモリなどのサーバースペックを下げること | - |
| スケールイン | サーバーの台数を減らすことでシステムの性能を最適化させること | - |
| スケールアウト | サーバーの台数を増やすことで、システムの処理能力を高めること | - |
| ステートフル、ステートレス | クライアントとサーバー間のやりとりにはステートフルとステートレスという仕組みが2通りある。ステートフルとは前回のデータを保存して、データ保存した内容を処理結果に反映される仕組みのこと。ステートレスとは前回のデータを保存しないで、前回のデータを内容に処理結果に反映させない仕組みのこと | 130 |
| 疎結合 | システムの構成要素間の結びつきや互いの依存関係、関連性などが弱く、各々の独立性が高い状態のこと | 36 |
| ダウンタイム | 常時使用できることが期待される機器やシステム、回線、サービスなどが停止・中断している時間。理由や原因を問わず止まっている時間の総体を指す。 | 64 |
| ディザスタリカバリー | 災害時のシステム障害を素早く復旧・修復を行うための仕組みや体制 | 34 |
|
ノード |
Amazon ElastiCache のデプロイにおける最小の構成要素 | 122 |
| ハイパーバイザー | コンピュータを仮想化し、複数の異なるオペレーティングシステム(OS)を互いに干渉させずに並行して動作させられるようにするソフトウェア | 50 |
| ブートストラップ | インスタンスを起動する最初の一回だけ実行されるもので、最初に実行したいコマンドを事前にシェルで書いておいておくことで、初期設定やソフトのインストールを自動で行うことができる | 130 |
| フェイルオーバー | 稼働中のシステムに障害が発生した際に、代替システムがその機能を自動的に引き継ぎ、処理を続行する仕組み | 80 |
| フォールトトレランス | システムや機器の一部が故障・停止しても、予備の系統に切り替えるなどして機能を保ち、正常に稼働させ続ける仕組み。「アベイラビリティ」と混同されやすいが、アベイラビリティは障害を防止することに主眼を置いており、フォールトトレランスは障害発生後にどれだけ通常の機能を保ち続けられるかを目的にしている | 253 |
| プラットフォーム | ある機器やソフトウェアを動作させるのに必要な、基盤となる装置やソフトウェア、サービス、あるいはそれらの組み合わせ(動作環境)のこと | |
| ブロックストレージ | ブロックストレージは、記録領域をボリュームという単位に分割し、ボリュームの内部をさらに固定長のブロックという単位に分割して管理するストレージです。身近な例では、PCやサーバーに搭載されているハードディスクや、USBメモリがブロックストレージにあたる | 165 |
| プロビジョニング | システム設計・構築(処理ピーク時の処理件数、1件あたりのデータサイズ、日次の処理件数などから機材の台数を設計) | 29 |
| マネージドサービス | 通信サービスやITサービスなどのうち、サービスの利用に必要な機器やソフトウェアの導入や管理、運用などの業務も一体的に請け負うサービスのこと | 36 |
| ユースケース | システムの使用例 | 105 |
| ルート | ネットワーク上でデータが送信元から宛先まで伝送される間に通過する中継機器(のアドレス)やネットワークの連なりのことをルート | 198 |
| レイテンシー | データ転送における指標のひとつで、転送要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間のことをいう。この遅延時間が短いことをレイテンシが小さい(低い)、遅延時間が長いことをレイテンシが大きい(高い)と表現される | 64 |
|
レプリケーション (レプリケート) |
「複製(レプリカ)を作ること」の意味。同じネットワーク内、もしくは遠隔地にサーバーを設置し、リアルタイムにデータをコピーする技術のこと |
80 (166) |
❏ ハンズオン
|
アカウント作成(ルートアカウント) ◯手順参考先 サイト - AWSを無料で利用する方法を実際にやってみて注意点まとめてみた。リンク > AWS アカウント作成の流れ ◯ハマった事 特になし ◯メモ フルネームは本名をローマ字で入力。住所は英語表記で記入する。 ◯参考書 3-2 AWSクラウドのセキュリティ(49頁) > 管理プレートの保護 |
|
EC2インスタンス生成 ◯手順参考先 サイト - AWSを無料で利用する方法を実際にやってみて注意点まとめてみた。リンク > > EC2でサーバーを作る ◯ハマった事 EC2インスタンスにPuttyからログインする際、 ・IPにはパブリックIPを指定する ・秘密鍵にはPEMファイルから変換したPPKファイルを指定する。変換はPuTTYgenツールで可能 ・アカウトは固定 ◯メモ ・Puttyセッション一覧:aws_user_name ・ストレージ確認(ルートデバイス:/dev/xvda) $ df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 8.0G 1.5G 6.6G 19% / ◯参考書 5-1 EC2 > EC2インスタンスの起動(109頁) |
|
請求アラート設定 ◯手順参考先 サイト - AWSを無料で利用する方法を実際にやってみて注意点まとめてみた。リンク > > 【請求アラート設定】 ◯ハマった事 特になし ◯メモ アカウント名をクリック > マイ請求ダッシュボード > 左下の「請求書」 > 右端の「+すべて展開」をクリックすることで、 詳細な情報(使用時間、使用容量、金額など)を確認できる ◯参考書 10-2 請求ダッシュボード > 請求アラーム(274頁) |
|
AWS Budgets ◯手順参考先 YouTube - AWS Budgetsで予算を管理しよう - serverworks( 5:54) リンク ◯ハマった事 アラート枠が表示されなかった・・ ◯メモ 予算額の80%を超えたらアラートメールを送信してくれる。全体のほかサービス単位でも登録可能。登録は2件まで無料。 ◯参考書 10-1 AWS料金モデル > 請求アラーム(274頁) |
|
アラームの作成(CloudWatch) ◯手順参考先 サイト - AWSを無料で利用する方法を実際にやってみて注意点まとめてみた。リンク > アラームの作成 ◯ハマった事 「概算合計請求額」クリック後の一覧には明細がなぜか表示されないので、「全てチェックボックス」をオンして「メトリクスの選択」をクリックする 遷移先のメトリクス名には「EstimatedCharges」と表示されていて、当サイトの内容と一致した ◯メモ リージョンを「US East (バージニア北部)」にする必要がある 設定金額は100以上にした ◯参考書 9-1 CloudWatch > CloudWatchの特徴(246頁) > SNSへの通知 10-1 AWS料金モデル > 請求アラーム(274頁) ◯その他 YouTube - 【AWS Black Belt Online Seminar】Amazon CloudWatch(47:14)リンク |
|
アカウントを解約 ※最後にやる ◯手順参考先 AWS アカウントを解約するにはどうすればよいですか? ◯ハマった事
◯メモ
◯参考書
|
|
Auto Scaling ◯手順参考先 ELBとAuto Scalingを使用したスケーラブルなWebアプリケーション(133頁) ◯ハマった事 ・AMIの選択で「Amazon Linux 2」を選びたいが見つからない。インスタンス生成時のAMI選択画面で無料利用枠の AMI ID (64 ビット x86のほう) で検索した ・ステップスケーリングの追加でスケールアウトされなかった ◯メモ 133頁にメモを追記 ◯参考書 5-3 Auto Scaling > アプリケーションデプロイの自動化(131頁) ELBとAuto Scalingを使用したスケーラブルなWebアプリケーション(133頁) |
|
VPCの作成 ◯手順参考先 構成例:基本構成でWebサーバーを起動(201頁) YouTube - 【AWS Black Belt Online Seminar】Amazon VPC(52:33) リンク ◯ハマった事 ・VPCを作成する開始画面を間違えた 誤:サービス > VPC 遷移先の「VPC ウィザードの起動」ボタン 正:サービス > VPC 遷移先のリージョン別のリソースの下にある「VPC」リンク先の「VPCを作成」ボタン ◯メモ 201頁にメモを追記 ◯参考書 7-1 VPC > 構成例:基本構成でWebサーバーを起動(201頁) ◯その他
YouTube - 【AWS Black Belt Online Seminar】Amazon VPC(52:33)
リンク |
|
IAMユーザの設定 ◯手順参考先 YouTube - 管理用IAMユーザーを作成しよう - serverworks(7:43) リンク ◯ハマった事 特になし ◯メモ 【IAMグループの作成】※管理者権限を持つIAMグループ
1. IAM > グループ > 新しいグループの作成 の順にクリック 【IAMユーザーの作成 】 1. IAM > ユーザー > ユーザーを追加 の順にクリック 2. ユーザー名「my_user」 3. AWS アクセスの種類を選択:AWS マネジメントコンソールへのアクセスをオン。それ以外はデフォルトのまま 4. [次のステップ:アクセス権限]をクリック 5. 先程作成したグループ名「Administrator」をONにして[次へ] をクリック 6. タグの追加は指定なし 7. [ユーザーの作成] をクリックして、[.csvのダウンロード] をクリック 8. ダウンロードファイルに記載されたURLにアクセスし、記載されたユーザー、パスワードをコピーしてサインインする 【MFAの設定】 1. 画面右上のユーザーをクリック > マイセキュリティ資格情報 の順にクリック 2. [MFAデバイスの割り当て] をクリック 3. 割り当てる MFA デバイスのタイプを選択:仮想 MFA デバイス を選択 4. iphoneにインストールした「Google Authenticator(オーセンティケーター)」アプリケーションにQRコードを読み込ませる ※インストール面倒だからやらない 5. MFAコード1、MFAコード2を入力して「MFAの割り当て] をクリック 【MFAの確認】 1. サインアウトする 2. サインインして、ユーザー、パスワードとMFAコードをん入力 【AWS Security Token Service(STS)について】 ・一時的なセキュリティ認証情報を発行する仕組み ・認証情報とはアクセスキーID、シークレットアクセスキー、セキュリティトークンのこと ・有効期限に数分から数時間のタイマーを設定できる ・リクエストに応じて動的に生成する 【IAMロールの仕組みについて】 1. IAMロールをアタッチしたECインスタンス上のアプリケーションがAWSリソースにアクセスする場合、 IAMロールがAWS STSに対してAWSリソースへのアクセス権限のリクエストを行う 2. AWS STSは有効期限付きの認証情報をIAMロールに返却する 3. アプリケーションは受け取った一時的認証情報を使ってAWSリソースにアクセス可能になる ※生成された認証情報は有効期限付きなのでIAMロールを使用するとセキュリティー上ののリスクを軽減出来る ◯参考書 3-3 IAM(59頁) ◯その他 YouTube - IAMロール - serverworks(7:26) リンク 補足:IAMロールの仕組み、クロスアカウントアクセス、IDフェデレーション YouTube - くろかわこうへいのAWS講座IAM編#1(15:10) リンク 補足:スイッチロール、IAM関連の用語 YouTube - くろかわこうへいのAWS講座IAM編#2( 4:48) リンク 補足:ポリシー(JSON)mの構文について サイト - IAMのスイッチロールを理解したい リンク 補足:スイッチロールの設定手順 |
|
ボリュームの変更 ◯手順参考先 サイト -EC2 EBS ボリュームサイズ拡張のやりかた リンク ◯ハマった事 特になし ◯メモ ※以下の手順はインスタンス実行中 AND ボリュームアタッチ済みの状態でも可能 1. 現状の確認 $ df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 482M 0 482M 0% /dev
tmpfs tmpfs 492M 0 492M 0% /dev/shm
tmpfs tmpfs 492M 408K 492M 1% /run
tmpfs tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 xfs 8.0G 2.4G 5.7G 30% /
tmpfs tmpfs 99M 0 99M 0% /run/user/1000
-------------------------------------------------------------------------------------------------- $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└-xvda1 202:1 0 8G 0 part /
2. ボリューム > 対象ボリュームを選択 > アクション > ボリュームの変更の順にクリック 3. サイズを変更して[変更]をクリック 4. OSファイルシステムを拡張する ※OS起動時にEBSのサイズに合わせてパーティションサイズを変更するツール $ which growpart
/usr/bin/growpart
-------------------------------------------------------------------------------------------------- $ sudo growpart /dev/xvda 1
CHANGED: partition=1 start=4096 old: size=16773087 end=16777183 new: size=20967391 end=20971487
-------------------------------------------------------------------------------------------------- $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
└xvda1 202:1 0 10G 0 part /
5. この段階ではまだ df -h しても変わってない $ df -h | grep xvda1
/dev/xvda1 8.0G 2.4G 5.7G 30% /
6. XFSファイルシステムとext4ファイルシステムで対応するコマンドが違うので、まずはファイルシステム確認 $ df -hT | grep xvda1
/dev/xvda1 xfs 8.0G 2.4G 5.7G 30% / ※xfs
-------------------------------------------------------------------------------------------------- XFSファイルシステムの場合 $ sudo xfs_growfs -d /
meta-data=/dev/xvda1 isize=512 agcount=4, agsize=524159 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1 spinodes=0
data = bsize=4096 blocks=2096635, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 2096635 to 2620923
-------------------------------------------------------------------------------------------------- ext4ファイルシステムの場合 $ sudo resize2fs /dev/xvda1
7./dev/xvda1のサイズが10Gに変更された $ df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 482M 0 482M 0% /dev
tmpfs tmpfs 492M 0 492M 0% /dev/shm
tmpfs tmpfs 492M 464K 492M 1% /run
tmpfs tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 xfs 10G 2.4G 7.7G 24% /
tmpfs tmpfs 99M 0 99M 0% /run/user/1000
tmpfs tmpfs 99M 0 99M 0% /run/user/0
◯参考書 6-1 EBS(165頁)
|
|
ボリュームの追加 ◯手順参考先 サイト -EC2インスタンスに追加でEBSボリュームをアタッチする リンク ◯ハマった事 特になし ◯メモ 1. 現状の確認 $ df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 482M 0 482M 0% /dev
tmpfs tmpfs 492M 0 492M 0% /dev/shm
tmpfs tmpfs 492M 464K 492M 1% /run
tmpfs tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 xfs 10G 2.4G 7.7G 24% /
tmpfs tmpfs 99M 0 99M 0% /run/user/1000
tmpfs tmpfs 99M 0 99M 0% /run/user/0
-------------------------------------------------------------------------------------------------- $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
└-xvda1 202:1 0 10G 0 part /
2. ボリューム > ボリュームの作成 の順にクリック 3. サイズを[2]Gに変更 4. アベイラビリティゾーンを追加するEC2インスタンスと同じにする 5. [ボリュームの作成]をクリック 6. 画面更新てし追加されたボリュームの状態がavailableであることを確認 7. 追加されたボリュームを選択 > アクション > ボリュームのアタッチ の順にクリック 8. 以下を設定して[アタッチ]をクリック ・インスタンス:i-0533de072937bcead ・デバイス:/dev/sdf 9. アタッチしたボリュームの状態がin-useであることを確認 10. 追加されたことおを確認。 $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
└-xvda1 202:1 0 10G 0 part /
xvdf 202:80 0 2G 0 disk ※ sdfはxvdfで表示される
11. ファイルシステムを作成 $ sudo mkfs -t xfs /dev/xvdf ※xvda1と同じxfsを指定
meta-data=/dev/xvdf isize=512 agcount=4, agsize=131072 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0
data = bsize=4096 blocks=524288, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0ボリュームのマウント
12. ファイルシステムが作成された事を確認 $ sudo file -s /dev/xvdf
/dev/xvdf: SGI XFS filesystem data (blksz 4096, inosz 512, v2 dirs)
13. マウントポイントを作成しマウントする $ sudo mkdir /data
$ sudo mount /dev/xvdf /data
14. 使用可能になったことを確認 $ df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 482M 0 482M 0% /dev
tmpfs tmpfs 492M 0 492M 0% /dev/shm
tmpfs tmpfs 492M 468K 492M 1% /run
tmpfs tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 xfs 10G 2.4G 7.7G 24% /
tmpfs tmpfs 99M 0 99M 0% /run/user/1000
tmpfs tmpfs 99M 0 99M 0% /run/user/0
/dev/xvdf xfs 2.0G 35M 2.0G 2% /data ※使用可能になった
15. root以外にも出力権限を付与 $ ls -l / | grep data
drwxr-xr-x 2 root root 6 Mar 27 02:41 data
$ sudo chmod 777 -R /data
16. 確認 $ cd /data
$ dd if=/dev/zero of=1G.dummy bs=1M count=1000
$ ls
1G.dummy
17. EC2いスタンスを停止→開始した状態では、アンマウントされるので、自動でマウントするように設定 $ sudo vi /etc/fstab
/dev/xvdf /data xfs defaults,nofail 0 2 ※この行を追加
$ sudo mount -a
※EC2いスタンスを停止→開始した状態でもマウントされている事を確認できた ◯参考書 6-1 EBS(165頁)
|
|
EC2インスタンスからS3へのアクセス設定 ◯手順参考先 サイト - Amazon EC2(Amazon linux)から直接S3へのファイルコピー リンク ◯ハマった事 特になし ◯メモ 【EC2インスタンス】 1. 以下の設定を行いEC2インスタンスを生成 ・ネットワーク:デフォルト ・サブネット:アベイラビリティゾーンのデフォルトサブネット ・タグ:Name:EC2S3 2. S3へコピーするテストファイルの準備 $ sudo su root
# yum -y update
# cd /home
# mkdir ./test-share
# cd ./test-share
# touch test.txt
# ls -l
【ロール】 1. IAM > ロール > ロールの作成 の順にクリック 2. 以下の設定を行い[ロールの作成]をクリック ・ユースケース:EC2 ・ポリシー:AmazonS3FullAccess ・ロール名「Demo_Role_EC2S3」 3. EC2コンソール > EC2を選択 > アクション > セキュリティ > IAM ロールを変更 の順にクリック 4. ロール名「Demo_Role_EC2S3」を選択して[保存]をクリック 【S3バケット】 1. S3 > バケットを作成 の順にクリック 2. 以下の設定を行い[バケットを作成]をクリック ・バケット名「demo-1142-bkt」 ・AWSリージョン:東京 ・その他はすべてデフォルト 3. AWS CLIでS3へデータをコピー $ sudo su root
# cd /home/test-share/
# aws s3 cp test.txt s3://demo-1142-bkt
upload: ./test.txt to s3://demo-1142-bkt/test.txt
# aws s3 ls s3://demo-1142-bkt/test.txt
2021-03-28 12:29:19 0 test.txt
◯参考書 6-2 S3(170頁) |
|
複数サービスを用いてWeb サイトをインターネット上に公開
◯手順参考先
サイト - 初心に戻って AWS で静的 Web サイトを作成する リンク 1.Amazon Simple Storage Service(S3)&静的ウェブサイトホスティング ◯ハマった事 特になし ◯メモ 【S3バケット】 1. S3 > バケットを作成 の順にクリック 2. 以下の設定を行い[バケットを作成]をクリック ・バケット名「demo-some-serv.ml」 ・AWSリージョン:東京 ・パブリックアクセスをすべて ブロック:OFF ・その他はすべてデフォルト 【静的ウェブサイトホスティング】 1. バケット名「demo-some-serv.ml」を選択 > プロパティタブ > 静的ウェブサイトホスティングの [編集] の順にクリック 2. 以下の設定を行い [変更の保存] をクリック ・静的ウェブサイトホスティング:有効にする ・ホスティングタイプ:静的ウェブサイトをホストする(デフォルト) ・インデックスドキュメント:index.html ・エラードキュメント - オプション:error.html ・リダイレクトルール – オプション:なし 【バケットポリシーを作成】 1. バケット名「demo-some-serv.ml」を選択 > アクセス許可タブ > バケットポリシーの [編集する] の順にクリック 2. 以下を埋め込み [変更の保存] をクリック。Resourceにはバケット名を指定する {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::demo-some-serv.ml/*"
]
}
]
}
3. バケット名「demo-some-serv.ml」に”パブリックにアクセス可能”、アクセス許可の概要に"⚠公開"と表示される事を確認 【ファイルアップロード】 1. index.htmlをバケットにアップロード 2. error.htmlをバケットにアップロード 【確認】 1. バケット名「demo-some-serv.ml」を選択 > プロパティタブ > 静的ウェブサイトホスティング へ移動 2. バケットウェブサイトエンドポイントのURLをクリック。 index.htmlの内容がブラウザに表示された事を確認 http://demo-some-serv.ml.s3-website-ap-northeast-1.amazonaws.com ◯参考書 6-2 S3(170頁)
◯その他
2.AWS Cloud9でindex.htmlを作成 ◯ハマった事 特になし ◯メモ 【Cloud9の起動】 1. Cloud9 > Create environment の順にクリック 2. 以下の設定を行い [Next step] をクリック ・Name:demo_some_service 3. Configure settingsで以下の設定を行い [Next step] をクリック ※すべてデフォルト ・Environment type:Create a new EC2 instance for environment (direct access) ・Instance type:t2.micro (1 GiB RAM + 1 vCPU) ・Platform:Amazon Linux 2 (recommended) ・Cost-saving setting:After 30 minutes(default) 4. [Create environment] をクリック 5. Cloud9の画面に遷移する。EC2インスタンス一覧にはaws-cloud9-demo-some-service-XXXXXという名前で生成されていた 【Cloud9でindex.htmlを編集後、AWS CLIでS3へアップロード】 1. windowsのindex.htmlをUTF-8に置換 2. 作業ディレクトリを作成 $ mkdir temp
$ cd temp
3. 左側メニューのtempディレクトリーを選択して、Fileタブの [Upload Local Files...] でindex.htmlをアップロード 5. 左側メニューのindex.htmlを選択。右クリックして [OPEN] を選択 6. 適当に編集を行う 7. Fileタブの [Save] で保存 8. Previewタブの Preview File index.html で表示を確認 9. AWS CLIでS3へアップロード $ aws s3 cp index.html s3://demo-some-serv.ml
upload: ./index.html to s3://demo-some-serv.ml/index.html
10. 静的ウェブサイトホスティングのURL(バケットウェブサイトエンドポイント)でindex.htmlの変更を確認 【Cloud9でcssファイルと画像を設定し、AWS CLIでS3へアップロード】 1. cssフォルダーとimgフォルダーを作成し、各々適当にファイルを格納。その一式を再帰的オプション(--recursive)を付けてS3へアップロード $ cd temp
$ mkdir css img
$ ls
css img index.html
$ aws s3 ls s3://demo-some-serv.ml
2021-04-05 11:52:03 121 error.html
2021-04-06 12:38:37 149 index.html
$ aws s3 cp . s3://demo-some-serv.ml --recursive
$ aws s3 ls s3://demo-some-serv.ml --recursive
2021-04-05 11:52:03 121 error.html
2021-04-08 12:20:12 247 index.html
2021-04-08 12:20:12 21842 img/demo.JPG
2021-04-08 12:20:12 0 css/styles.css
【動作確認】 静的ウェブサイトホスティングのURL(バケットウェブサイトエンドポイント)でindex.htmlの変更を確認 ◯参考書 なし ◯その他 YouTube -AWS Cloud9とは?初心者向けに登録方法や使い方を紹介 (8:39) リンク 補足:はじめ方 YouTube -Cloud9とは?【分かりやすい解説シリーズ #27】【プログラミング】(6:44) リンク 補足:メリット・デメリット
3.Amazon CloudFrontで画像をキャッシュ ◯ハマった事 特になし ◯メモ 【CloudFrontの作成】 1. CloudFront > Create Distribution > Get Started の順にクリック 2. 以下の設定を行い [Create Distribution] をクリック *Origin Settings ・Origin Domain Name:作成したS3バケットを選択 ・Restrict Bucket Access:Yes (S3コンテンツへのアクセスがCloudFront経由のみに限定される) ・Origin Access Identity:Create a New Identity (S3コンテンツへアクセスするためのIdentityを作成する) ・Grant Read Permissions on Bucket:Yes, Update Bucket Policy (アクセス許可を自動的に付与する) *Default Cache Behavior Settings ・Viewer Protocol Policy:Redirect HTTP to HTTPS (HTTPリクエストをHTTPSにリダイレクトする) *Distribution Settings ・Default Root Object:index.html (ルートURL(開始画面)を指定) 3. 一覧でStatus:Deployed、state:Enabledになったら作成完了 4. S3 > アクセス許可タブ のバケットポリシーが更新されていることを確認 その他のパブリックアクセスはすべてブロックのまま、静的ウェブサイトホスティングは無効のままになっている つまりS3コンテンツへのアクセスはCloudFront経由のみに限定された状態である 【動作確認】 CloudFront一覧のDomain Name列の値をコピーして、ブラウザも貼り付けindex.htmlが表示され事を確認する ◯参考書 7-2 CloudFront(213頁) ◯その他 YouTube -【AWS入門: フロントエンドエンジニアのための】#2 ~CloudFrontの理解~(12:27) リンク 補足:メリット、導入手順
4.Route 53 を使い、独自ドメインでWebサイトを公開 ◯ハマった事 Freenomでドメイン登録をPC、メールは携帯だと下記「Nameserverの設定 > 3.」でエラーになる ◯メモ 【Freenomでドメイン取得】
1. freenonにアクセス 2. 「新しい無料ドメインを探します」と記載されている入力項目に「demo-some-serv」と入力 3. 「.ml」の [今すぐ入手!] をクリック。何故か利用不可といわれる。「demo-some-serv.ml」で再検索 4. [チェックアウト] をクリック 5. [12 Months @ FREE] を選択して [Continue] をクリック 【Freenomでアカウントを作成 】 1. メールアドレスを入力して [Verify My Email Address] をクリック 2. 24時間以内にメールを確認しリンクをクリック 3. 名前、住所等を入力して、同意にチェックして [Complete Order] をクリックして完了 【AWSで発行したNameserverをFreenomで発行したドメインに設定】 1. Route 53 > ホストゾーンの作成 で以下を設定して [ ホストゾーンの作成] をクリック ・ドメイン名:demo-some-serv.ml ※Freenomで登録したドメイン ・タイプ:パブリックホストゾーン 2. freenom > サインイン > Services > My Domains で表示される一覧 > Manage Domain の順にクリック 3. Management Toolsで「Nameservers」を選択 > Use custom nameservers (enter below) の順にクリック 4. Route 53 > ホストゾーン > demo-some-serv.ml の一覧を表示 5. 一覧のタイプ列が「NS」の値列に記載された4件のNameserverをコピー 6. コピーした4件をドメインに紐付けるため、freenom(上記「3.」)に入力して [change Nameservers] をクリック ◯参考書 7-3 Route 53(217頁) ◯その他 YouTube -【AWS入門: フロントエンドエンジニアのための】#3 ~Route 53の理解~(19:23) リンク 補足:Freenom、Route 53、ACMの設定 サイト - Freenomでのドメイン取得方法 リンク
5.AWS Certificate ManagerでHTTPS アクセス ◯ハマった事 特になし ◯メモ 【AWS Certificate ManagerでCNAMEを発行】 1. AWS Certificate Manager を表示 2. リージョンを「バージニア北部」に変更 3. 証明書のプロビジョニングの [今すぐ始める] をクイック 4. パブリック証明書のリクエストが選択された状態で [証明書のリクエスト] をクリックし、以下の設定を行い [次へ] ・ドメイン名の入力項目:Freenomで登録したドメイン「demo-some-serv.ml」 ・[この証明書に別の名前を追加] をクリックした時の入力項目:*.demo-some-serv.ml ※www.demo-some-serv.mlなども保護される 5. DNSの検証が選択された状態で [次へ] をクリック 6. タグなし > 確認 > 確認とリクエスト の順にクリックすると、CNAME レコードの名前と値が表示される 7. 検証状態は「検証保留中」であることを確認 【ACMで発行したCNAMEをRoute 53に設定】 1. 別タブで、Route 53 > ホストゾーン > demo-some-serv.ml の一覧を表示 2. [レコードを作成] をクリックして、以下の設定を行い、[レコードを作成] をクリックする ・レコード名:上記「ACMの設定 > 6.」のCNAME レコードの名前 ※名前末尾の「.demo-some-serv.ml.」は削除する ・レコードタイプ:CNAME ・値:上記「ACMの設定 > 6.」のCNAME レコードの値 3. 数分すると上記「7.」の検証状態は「成功」、一覧の状況は「発行済み」に状態遷移する 【 CloudFrontの変更】 1. CloudFront一覧 > ID列の値(リンク) > GeneralタブのEdit の順にクリック。以下の設定を行い [Yes, Edit] をクリック ・Alternate Domain Names(CNAMEs):demo-some-serv.ml ・Custom SSL Certificate (example.com):ONにして、リストボックスからdemo-some-serv.mlを選択 【Route 53のAレコード設定】 1. さきほど別タブで表示した、Route 53 > ホストゾーン > demo-some-serv.ml の一覧を表示 2. [レコードを作成] をクリックして、以下の設定を行い、[レコードを作成] をクリックする ・レコード名:<空白> ・レコードタイプ:A - IPv4 ・エイリアス:ON(値の右側にあるスイッチ)にして、各リストボックスで以下を選択 ・エイリアスのリストボックス - 1行目:CloudFrontディストリビューションへのエイリアス ・エイリアスのリストボックス - 2行目:米国東部(バージニア北部) ・エイリアスのリストボックス - 3行目:CloudFrontのDomain Name 【動作確認】 1. demo-some-serv.mlをブラウザも貼り付けindex.htmlが表示され事を確認する 2. URL左側の鍵マークをクリックすると「この接続は保護されています」と表示されている 3. URL左側の鍵マークをクリックして証明書を選択すると、発行元が「Amazon」になっている 4. URLをテキストエディターに貼ると、スキームが「https」になっている ◯参考書 7-2 CloudFront > CloudFrontの特徴(213頁) ◯その他 YouTube -【AWS入門: フロントエンドエンジニアのための】#3 ~Route 53の理解~(19:23) リンク 補足:Freenom、Route 53、ACMの設定
6.リソースの削除 12時間以内に削除すれば課金されない ◯ハマった事 特になし ◯メモ 1. Aレコードを削除 2. CNAMEレコードを削除 3. ホストゾーンを削除 ◯参考書 なし ◯その他 YouTube -【AWS入門: フロントエンドエンジニアのための】#3 ~Route53の理解~(19:23) リンク 補足:Freenom、Route53、ACMの設定
|
|
複数サービスを用いてRDSからS3へExportして&AthenaからSQLを実行
|
|
1.RDSの構築 & EC2からRDSに接続 ◯手順参考先 サイト - RDS for MySQLを構築しEC2からアクセスしてみる リンク ◯ハマった事 ・RDSの作成時、VPC セキュリティグループでEC2と同じlaunch-wizard-1を選択し接続できなかった。正解:demo-athena-Secure ・サブネットグループはAZを2箇所設定する必要があるが、RDSとEC2のAZを一致させないと接続できなかった ◯メモ 【DB用セキュリティグループの作成】 1. EC2 > セキュリティグループ > セキュリティグループの作成 の順にクリック 2. 基本的な詳細に以下を設定する ・セキュリティグループ名:demo-athena-Secure ・説明:demo-athena-Secure ・VPC:DB接続するEC2インスタンスと同じ 3. インバウンドルール ・タイプ:MYSQL/Aurora ・ソース:カスタム|DB接続するEC2インスタンスと同じセキュリティグループを指定 4. [セキュリティグループの作成 ] をクリック 【DB用サブネットグループの作成】 1. RDS > サブネットグループ > DB サブネットグループの作成 の順にクリック 2. サブネットグループの詳細に以下を設定する ・名前:demo-athena-subnet ・説明:demo-athena-subnet ・VPC:DB接続するEC2インスタンスと同じ 3. サブネットを追加に以下を設定する ・アベイラビリティーゾーン:DB接続するEC2インスタンスと同じ(2箇所) ・サブネット:各アベイラビリティーゾーンのサブネット 4. [作成] をクリック 【データベースの作成】※このときのバージョン:MySQL8.0.20 1. RDS > データベース > データベースの作成 の順にクリックして、以下を設定 ・データベース作成方法を選択:標準作成 ・エンジンのオプション:MySQL ・テンプレート:無料利用枠 ・DB インスタンス識別子:database-1(デフォルト) ・マスターユーザー名:admin(デフォルト) ・マスターパスワード:password ・DB インスタンスサイズ:db.t2.micro 1GiB(デフォルト) ・ストレージ:20GiB(デフォルトのまま。最小が20GiB) ・VPC:DB接続するEC2インスタンスと同じ ・サブネットグループ:demo-athena-subnet ・パブリック・アクセス:なし(デフォルト) ・VPC セキュリティグループ:既存の選択 ・既存の VPC セキュリティグループ:demo-athena-Secure ・アベイラビリティゾーン:ap-northeast-1a ・データベース認証オプション:パスワード認証(デフォルト) 2. [データベースの作成] をクリック 【EC2からRDSに接続】 1. EC2にログイン 2. MySQLをインストール $ sudo yum install mysql
3. MySQLにログイン(パスワード:pssword) $ mysql -u admin -p -h <RDSのエンドポイント>
◯参考書 8-1 RDS(227頁) |
|
2.RDSにデータを生成 ◯手順参考先 サイト - MySQLでのサンプル用データベースの作成 リンク 備考:DB生成からINSERT サイト - [MySQL] テーブルにファイルをインポートする リンク 備考:インポート手順 サイト - テストデータ生成 リンク 備考:テストデータの生成 ◯ハマった事 ユーザーに権限を付与しないとインポートできない サイト - amazon-web-services - mysqlimport:エラー:MySQL 8.0およびAmazon RDSで1227アクセスが拒否されました リンク ◯メモ 【DB・テーブル生成およびデータ挿入:CREATE、INSERT】 1. DB生成 mysql> create database sample;
2. テーブル生成 mysql> create table staff
(
id integer,
name char(16),
branch char(20),
age integer
);
3. データを挿入 mysql> INSERT INTO staff (id, name, branch, age) VALUES ('1','Tanaka','Tokyo','29');
mysql> INSERT INTO staff (id, name, branch, age) VALUES ('2','Yamada','Yokohama','31');
mysql> INSERT INTO staff (id, name, branch, age) VALUES ('3','Sugiura','Chiba','34');
mysql> INSERT INTO staff (id, name, branch, age) VALUES ('4','Yamano','Osaka','25');
mysql> INSERT INTO staff (id, name, branch, age) VALUES ('5','Nakajima','Yokohama','38');
mysql> INSERT INTO staff (id, name, branch, age) VALUES ('6','Suzuki','Tokyo','24');
4. 確認 MySQL [sample]> select * from staff;
+------+----------+----------+------+
| id | name | branch | age |
+------+----------+----------+------+
| 1 | Tanaka | Tokyo | 29 |
| 2 | Yamada | Yokohama | 31 |
| 3 | Sugiura | Chiba | 34 |
| 4 | Yamano | Osaka | 25 |
| 5 | Nakajima | Yokohama | 38 |
| 6 | Suzuki | Tokyo | 24 |
+------+----------+----------+------+
【インポート:mysqlimport】 1. テーブル生成 mysql> create table staff_details
(
id integer,
email varchar(30),
sex char(1),
tel char(13),
update_date char(8)
);
2. 権限付与 mysql> GRANT SESSION_VARIABLES_ADMIN ON *.* TO 'admin'@'%';
3. インポート $ mysqlimport -u admin -p -h database-1.clmnt3uyc5io.ap-northeast-1.rds.amazonaws.com --local sample staff_details.tsv
sample.staff_details: Records: 100 Deleted: 0 Skipped: 0 Warnings: 0
◯参考書 なし |
|
3.RDSからデータをSnapshot ◯手順参考先 特になし◯ハマった事 特になし ◯メモ 1. RDS > データベース > RDSを選択 > アクション >スナップショットの取得 の順にクリック 2. 以下を設定して [スナップショットを取得] をクリック ・スナップショット名:demo-snapshot 3. スナップショット一覧のステータスが利用可能になったら完了 ◯参考書 特になし |
|
4.SnapshotをS3へExport(KMSで暗号化) ◯手順参考先 YouTube -AWS Glueを使ってRDSから S3+Athena環境を作ってみよう #devio2020(22:49) リンク ◯ハマった事 RDSのステータスが「利用可能」でないとエクスポートを実行してもずっと「起動中」のままだった ◯メモ 【KMSの作成】 1. Key Management Service > キーの作成 の順にクリック。以下の設定を行い[次へ] をクリック ・キーのタイプ:対称 ・詳細オプション:KMS(デフォルト) 2.以下の設定を行い[次へ] をクリック ・エイリアス:demo_s3_kms 3.キーの管理アクセス許可を定義、及びキーの使用アクセス許可を定義とも<未指定>のまま [次へ] をクリック 4. [完了] をクリック
【S3バケットの作成】 1. S3 > バケットを作成 の順にクリック。以下を設定して [バケットを作成] をクリック ・バケット名:demo-export-rds ・AWS リージョン:アジア・パシフィック(東京) ・上記以外:<すべてデフォルト> 【snapshotをExport】 1. RDS > スナップショット > 一覧から選択 > アクション > Amazon S3 へのエクスポート の順にクリック。以下を設定 ・ 識別子:export-sample-for-athena ・エクスポートされたデータ:すべて(デフォルト) ・S3 バケット:demo-export-rds ・IAM ロール:「新しいロールの作成」を選択 ・IAM ロール名:export-role ・暗号化:demo_s3_kms 2. [Amazon S3 へのエクスポート] をクリック 3. スナップショット の一覧のステータスが「完了」になることを確認 4. スナップショット の一覧のS3バケットのリンクをクリックして以下を確認 ・トップがDB名である ・いくつかのJSONファイルが存在する ・DB名下にテーブル名がすべて存在する ・各テーブル名下にデータが存在する(parquet:パーケット形式) ◯参考書 6-2 S3 > S3のセキュリティ > 通信、保存データの暗号化(172頁) |
|
5.Glueクローラでデータカタログを生成(KMSで復号化) ◯手順参考先 YouTube -AWS Glueを使ってRDSから S3+Athena環境を作ってみよう #devio2020(22:49) リンク ◯ハマった事
◯メモ 【Glueクローラの設定】 1. Glue > 左側メニューのクローラ > クローラの追加 の順にクリック。以下を設定して [次へ] ・クローラの名前:demo_Crawler を設定して [次へ] ・Crawler source type:Data stores ・Repeat crawls of S3 data stores:Crawl all foldersr を設定して [次へ] ・データストアの選択:S3 ・接続:<未指定> ・インクルードパス:S3バケット名 > エクスポート名 > DB名 の順にクリックして [次へ] s3://demo-export-rds/export-sample-for-athena/sample ・別のデータストアの追加:いいえ ・IAM ロールの選択:IAM ロールを作成する ・IAM ロール名 AWSGlueServiceRole-:crawler-role を設定して [次へ] ・頻度:オンデマンドで実行 を選択して [次へ] 2. [データベースの追加] をクリック。以下を設定 ・データベース名:demo-crawler-db を設定して [次へ] 3. [完了] をクリック 【GlueクローラのIAM ロールに、暗号化されたS3バケットのデータを復号化する権限を設定】 1. IAM > ロール の順にクリック 2. 一覧で「AWSGlueServiceRole-」で検索。「AWSGlueServiceRole-crawler-role」を選択 3. インラインポリシーの追加 > サービスの選択 の順にクリック 4. サービスの検索で「kms」で検索 5. アクションで「decrypt」で検索。「Decrypt」を選択 6. リソース:すべてのリソース を選択 7. [ポリシーの確認] をクリック 8. 名前:demo-kms-decrypt 9. [ポリシーの作成] をクリック 【Glueデータカタログの作成】 1. Glue > 左側メニューのクローラ > 一覧でクローラを選択 > クローラの実行 の順にクリック 2. ステータスが「Ready」になったら、左側メニューからテーブルを選択 3. テーブルのかずだけデータカタログが作成されていることを確認 ◯参考書 特になし |
|
6.AthenaでSQL実行 ◯手順参考先 YouTube -AWS Glueを使ってRDSから S3+Athena環境を作ってみよう #devio2020(22:49) リンク ◯ハマった事 クエリで「demo-crawler-db.sample_staff」と設定するとクエリ実行でエラー「extraneous input '-'」になる どうやら「-:ハイフン」が使えないらしい( サイト - テーブル、データベース、および列の名前 リンク ) DB名を「":ダブルコーテーション」で括った「"demo-crawler-db".sample_staff」では正常に実行できた ◯メモ 1. S3 > demo-export-rds > export-sample-for-athena > フォルダーの作成 の順にクリック ・フォルダー名:result 2. サービス:athena を選択 3. 左側メニュー > Database:demo-crawler-db を選択 4. 右上に表示されているメッセージ内の「set up a query result location in Amazon S3.」をクリック 5. Query result locationに「result」フォルダーを選択:s3://demo-export-rds/export-sample-for-athena/result/ 6. [save] をクリック 7. sample_staffテーブルの「︙」をクリックして「Preview table」を選択 8. 右上でサンプルクエリが実行され、右下にクエリー結果が表示されればOK SELECT * FROM "demo-crawler-db"."sample_staff" limit 10;
9. JOINしてみた SELECT
a.id,
a.name,
b.email,
b.update_date
FROM
"demo-crawler-db".sample_staff a
INNER JOIN
"demo-crawler-db".sample_staff_details b
ON a.id = b.id
◯参考書 特になし |
|
7.ソースの削除 自分で作成したKMS(CMK)は毎日課金される。そして削除に最短7日間かかる ◯ハマった事 特になし ◯メモ 【KMSの削除】 1. KMS > 一覧から選択 > キーにアクション > キーの削除をスケジュール 2. 待機期間 (日数):7日後を選択して [削除をスケージュール] をクリック 3. 削除をスケージュール後はAthenaで[ErrorCode: INTERNAL_ERROR_QUERY_ENGINE]エラーになった ◯参考書 特になし ◯その他 サイト -カスタマーマスターキー を削除する リンク
またデータカタログが使用したいときはKMSの作成から再実行。以下は注意 ・各サービスの既存名に+1した名前で作成 ・IAMロールは「新しいロールの作成」を選択する ・データーベース名にハイフンを使用しない
|
|
Athenaのポイント ◯参考先 YouTube - 【AWS Black Belt Online Seminar】Amazon Athena(1:00:43) リンク |
|
Glueジョブ ◯手順参考先 サイト -AWS Glue のチュートリアルをやってみました リンク ◯ハマった事 特になし ◯メモ 【GlueのIAMロールを生成】 1. IAM > ロール > ロールを作成 の順にクリック。以下を設定して [次のステップ:アクセス権限] ・信頼されたエンティティの種類を選択:AWS サービス ・ユースケースの選択:Glue 2. 以下のポリシーを選択して [次へ] ・AWSGlueServiceRole ・AmazonS3FullAccess 3. 以下を設定して [ロールの作成] ・ロール名:AWSGlueServiceRoleDefaultCM ※ロール名は先頭にAWSGlueServiceRoleを付けるという命名規約があるらしい・・ 【データの用意】 1. S3 > バケットを作成 の順にクリック。以下を設定して [バケットを作成] ・バケット名:demo-export-tutorial ・AWS リージョン:ap-northeast-1 ・他は全てデフォルト 2. バケット一覧でdemo-export-tutorialを選択して各格納先フォルダーを作成 ・クロラーのINPUTデータ:crawler ・Glueジョブのスクリプト:script ・Glueジョブの一時ディレクトリ:temp ・Glueジョブの結果:result 3. s3://demo-export-tutorial/crawler/にクロラーのINPUTデータ(CSV)を格納 "id","name","branch","age"
"1","Tanaka","Tokyo","29"
"2","Yamada","Yokohama","31"
"3","Sugiura","Chiba","34"
"4","Yamano","Osaka","25"
"5","Nakajima","Yokohama","38"
"6","Suzuki","Tokyo","24"
【Glueジョブの生成】 1. Glue > 左側メニューのチュートリアル下のクローラの追加 >クローラの追加 の順にクリック 2. 以下を設定して [次へ] ・クローラの名前:Flight_Data_Crawler 3. 以下を設定して [次へ] ・Crawler source type:Data stores(デフォルト) ・Repeat crawls of S3 data stores:Crawl all folders(デフォルト) 4. 以下を設定して [次へ] ・データストアの選択:S3 ・接続:未選択 ・クロールするデータの場所:自分のアカウントで指定されたパス(デフォルト) ・インクルードパス:s3://demo-export-tutorial/crawler/ ※配下のファイル全てにするため末尾に/を付与 5. 以下を設定して [次へ] ・別のデータストアの追加:いいえ 6. 以下を設定して [次へ] ・IAM ロール:既存の IAM ロールを選択して「AWSGlueServiceRoleDefaultCM」を設定 7. 以下を設定して [次へ] ・頻度:オンデマンドで実行 8. [データベースの追加]をクリックして以下を設定して [次へ] ・データベース名:flight_data_crawler_db 9. [完了] 10. クローラ一覧でFlight_Data_Crawlerを選択して[クローラの実行]をクリック 11. クローラ完了後、 左側メニューのチュートリアル下のテーブルの確認をクリックして、一覧に「crawler」が作成されている事を確認 12. AthenaでDatabaseに「flight_data_crawler_db」があること、Tablesに「crawler」がある事を確認 【Glueジョブの作成】 1. Glue > 左側メニューのチュートリアル下のジョブの追加 >ジョブの追加 の順にクリック。以下を設定して [次へ] ・名前:flight_conversion ・IAMロール:AWSGlueServiceRoleDefaultCM ・Type:Spark(デフォルト) ・Glue version:Spark 2.4, Python 3 with improved job startup times (Glue Version 2.0 ) (デフォルト) ・このジョブ実行:AWS Glue が生成する提案されたスクリプト ・スクリプトファイル名:flight_conversion ・スクリプトが保存されている S3 パス:s3://demo-export-tutorial/script ・一時ディレクトリ:(デフォルト):s3://demo-export-tutorial/temp ・セキュリティ設定、スクリプトライブラリおよびジョブパラメータ (任意) ・参照されるファイルパス:なし ・作業者タイプ:標準 ・作業者数:2 ・カタログオプション (任意) ・Use Glue data catalog as the Hive metastore:ON 2. データソースの選択。以下を設定して [次へ] ・データソースの選択:crawler 3. 変換タイプを選択します。以下を設定して [次へ] ・スキーマを変更する:ON(デフォルト) ※「一致するレコードを検索する」は何故か選択できない 4. データターゲットの選択。以下を設定して [次へ] ・データターゲットでテーブルを作成する:ON ※更新も出来るらしい ・データストア:Amazon S3 ・形式:Parquet ・接続:なし ・ターゲットパス:s3://demo-export-tutorial/result 5. Output Schema Definition。とりあえず変更しないで [ジョブを保存してスクリプトを編集する]をクリック 6. スクリプト編集画面に遷移される 7. [保存]をクリック 8. [ジョブの実行]をクリック 9. ジョブ正常終了後、s3://demo-export-tutorial/resultにParquetファイルが生成されている事を確認
◯参考書 特になし |





AWS Glue が生成する提案されたスクリプト
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# データカタログからDynamicFrameを取得
## @type: DataSource
## @args: [database = "flight_data_crawler_db", table_name = "crawler", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "flight_data_crawler_db", table_name = "crawler", transformation_ctx = "datasource0")
# 変換するデータの項目マッピングを定義
## @type: ApplyMapping
## @args: [mapping = [("id", "long", "id", "long"), ("name", "string", "name", "string"), ("branch", "string", "branch", "string"), ("age", "long", "age", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("id", "long", "id", "long"), ("name", "string", "name", "string"), ("branch", "string", "branch", "string"), ("age", "long", "age", "long")], transformation_ctx = "applymapping1")
# choiceを解決
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
# タイプが NullType のすべての null フィールドを削除
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
# S3に書き込む
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://demo-export-tutorial/result"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://demo-export-tutorial/result"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
|
SageMaker ◯手順参考先 サイト - Amazon Athena を使用した SageMaker ノートブックからの SQL クエリの実行方法 リンク ◯ハマった事 Terminalをlogoutしてpython3を起動しようとしてエラーになった。Terminalのタブはそのままにしておく。 ◯メモ 【ノートブックインスタンスの作成】 1. SageMaker > 左側メニューのノートブック の ノートブック インスタンス > ノートブック インスタンスの作成 の順にクリック 2. 以下を設定して [ノートブック インスタンスの作成]をクリック ・ノートブックインスタンス名:demo-jupyter ・ノートブックインスタンスのタイプ:ml.t2.medium(デフォルト) ・Elastic Inference:なし(デフォルト) ・IAM ロール:新しいロールの作成を選択 「IAM ロールを作成する」ダイアログが表示される 以下を設定して[ロールの作成]をクリック ・指定する S3 バケット - オプション:任意の S3 バケット 3. ステータスが「InService」になるまで待機 【アクセスキーの作成】 1. 右上のアカウント > マイセキュリティ資格情報 > アクセスキー > 新しいアクセスキーの作成 の順にクリック 2. アクセスキー IDとシークレットアクセスキーをエディターにコピペ 【JupyterでPython3の起動】 1. 一覧から作成したインスタンスを選択 2. アクション > Jupyterを開く > ブラウザの別ウィンドウでノートブックのインターフェイスが開く 3. 右上の[NEW] から [Terminal] を選択 4. aws認証情報の更新を行う sh-4.2$ aws configure
AWS Access Key ID [None]: *************************
AWS Secret Access Key [None]: **********************************
Default region name [ap-northeast-1]: ap-northeast-1
Default output format [None]: json
5. 右上の[NEW] からAnacondaのPython3系環境 [conda_python3]を選択 【Python3を実行】 1. 左上のJupyterの右側の「Untitled」をクリックして以下を設定して[Rename] ・Rename Notebook:demo_conda_python1 2. 以下を入力して[Run] # Athena JDBC ドライバーをインストール
3.以下を入力して[Run] # AthenaにSQLを投げる
from pyathena import connect
import pandas as pd
conn = connect(s3_staging_dir='s3://demo-export-rds2/export-sample-for-athena2/temp_athena/',
region_name='ap-northeast-1')
df = pd.read_sql("SELECT * FROM flight_data_crawler_db.crawler limit 10;", conn)
df
【あとかたづけ(アクセスキーの削除)※重要】 1. Terminalで削除 sh-4.2$ rm -rf ~/.aws
2. 右上のアカウント > マイセキュリティ資格情報 > アクセスキー > アクションの削除 の順にクリック ◯参考書 特になし |

|
Lambdaを使用してEC2を自動で起動/停止 ◯手順参考先 サイト - Amazon EMR とは? リンク ◯ハマった事 ・ソースをコードエディターに貼っただけでは反映されない。[Deploy] をクリック「Changes deployed」にする必要がある ・Cron式はUTCで評価されるので、CloudWatchのCronで指定する時間は「9時間マイナス」する必要がある ◯メモ 【ポリシーとロールの生成】 1. IAM > ポリシー > ポリシーの作成 > JSONタブの順にクリック。以下を設定 {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"ec2:Start*",
"ec2:Stop*"
],
"Resource": "*"
}
]
}
2. 次のステップ:タグ > 次のステップ:確認 の順にクリック。以下を設定して [ポリシーの作成] をクリック ・名前:test_pol_lambda 3. IAM >ロール > ロールの作成 の順にクリック。以下を設定して [次のステップ:アクセス権限] をクリック ・信頼されたエンティティの種類を選択:AWS サービス ・ユースケースの選択:Lambda 4. フィルター「test_pol_lambda」を選択して 5. 次のステップ:タグ > 次のステップ:確認 の順にクリック。以下を設定して [ロールの作成] をクリック ・名前:test_rol_lambda 【Lambdaの設定】 1. Lambda > 関数の作成 の順にクリック。以下を設定して [関数の作成] をクリック ・オプション:一からの作成 ・関数名:test_ec2_lambda ・ランタイム:Python 3.7 ・実行ロール:既存のロールを使用する:test_rol_lambda 2. 以下のスクリプトを記入する(regionにアベイラビリティゾーン、instancesに起動するインスタンスIDを指定) import boto3
region = 'ap-northeast-1'
instances = ['i-043b891ff9021deb4']
ec2 = boto3.client('ec2', region_name=region)
def lambda_handler(event, context):
ec2.start_instances(InstanceIds=instances)
print('started your instances: ' + str(instances))
3. 設定タブ > 一般設定 > 編集 の順にクリック。以下を設定して [保存] をクリック ・タイムアウト:10秒 4. [Deploy] をクリック 5. [テスト] ボタンを押下して、以下を設定して [作成] をクリック。再度 [テスト] ボタンを押下 ・イベントテンプレート:Hello World ・イベント名:TestEvent 6. Execution Resultタブが表示されエラーが無ければ完了 【CloudWatchの設定】 1. Lambda > 関数 > test_ec2_lambda > 関数の概要内の「+トリガーを追加」の順にクリック。以下を設定して [追加] をクリック ・トリガーの設定:EventBridge(CloudWatch Events) ・ルール:新規ルール ・ルール名:test_start_ec2 ・ルールタイプ:スケジュール式 ・スケジュール式:cron(25 16 ? * SUN *) ◯参考書 5-4 Lambda(150頁) |
|
ア ◯手順参考先
◯ハマった事
◯メモ
◯参考書
|
情報収集(その他)
| 参考サイト | 概要 | URL |
|---|---|---|
| サイト - AWSの無料枠でできること3選|AWS無料枠を使用する際の注意点3つ |
無料枠のファイル数や容量等、AWS Budgets |
リンク |
|
サイト - AWS1年目無料期間でやったこととハマったこと |
幾つかの注意点、コミュニティや参考書の紹介 | リンク |
|
サイト - AWSで消し忘れを防止するためにチェックすべき7つのポイント |
課金されないために停止・終了した方が良いサービス | リンク |
| YouTube - AWS EC2入門 #05:Elastic IPで固定IPを取ろう(11:31) |
ELastic IPの取得、EC2インスタンスへの関連付け手順 |
リンク |
| YouTube - [AWS Black Belt Online Seminar] AWS Glue(55:30) |
Glueの概要等いろいろ |
リンク |
| YouTube - AWS Glueを使った Serverless ETL の実装パターン(39:15) |
Glueの概要、ETL処理の実装方法 |
リンク |
| サイト - AWS Lambda関数の呼び出しがAWS CLI v2にアップデートすると失敗する |
|
リンク |